iOS 知识整理
一.设计模式
面向对象特性:
1.封装
封装,也就是把客观事物封装成抽象的类,并且类可以把自己的数据和方法只让可信的类或者对象操作,对不可信的进行信息隐藏。 封装是对象和类概念的主要特性
2.继承
通过继承创建的新类称为“子类”或“派生类”,被继承的类称为“基类”、“父类”或“超类”。
3.多态
允许你将父对象设置成为和一个或更多的他的子对象相等的技术,赋值之后,父对象就可以根据当前赋值给它的子对象的特性以不同的方式运作。 覆盖,重载
面向对象编程原则:
| S | 单一功能原则 | 认为对象)应该仅具有一种单一功能的概念。 |
|---|---|---|
| O | 开闭原则 | 认为“软件体应该是对于扩展开放的,但是对于修改封闭的”的概念。 |
| L | 里氏替换原则 | 认为“程序中的对象应该是可以在不改变程序正确性的前提下被它的子类所替换的”的概念。参考契约式设计。 |
| I | 接口隔离原则 | 认为“多个特定客户端接口要好于一个宽泛用途的接口”[5]#cite_note-martin-design-principles-5) 的概念。 |
| D | 依赖反转原则 | 认为一个方法应该遵从“依赖于抽象而不是一个实例”[5]#cite_note-martin-design-principles-5) 的概念。 依赖注入是该原则的一种实现方式。 |
6 迪米特原则(Law of Demeter 又名Least Knowledge Principle)
迪米特法则来自于1987年美国东北大学(Northeastern University)一个名为“Demeter”的研究项目,又称最少知识原则(LeastKnowledge Principle, LKP),其定义如下:
迪米特法则(Law of Demeter, LoD):一个软件实体应当尽可能少地与其他实体发生相互作用。
一个类应该对自己需要调用的类知道得最少,类的内部如何实现、如何复杂都与调用者或者依赖者没关系,调用者或者依赖者只需要知道他需要的方法即可,其他的我一概不关心。
设计模式:
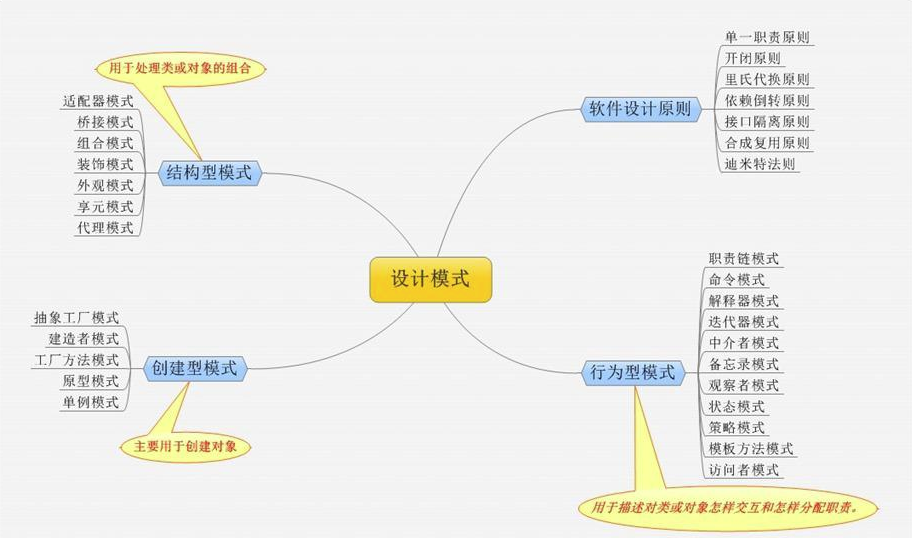
iOS常用设计模式:
1.单例
保证一个类仅有一个实例,并提供一个访问它的全局访问点。该类需要跟踪单一的实例,并确保没有其它实例被创建。单例类适合于需要通过单个对象访问全局资源的场合。
eg: 各种管理类,值传递,消息通信.(生命周期与应用程序绑定)
2.观察者
定义一种对象间一对多的依赖关系,使得当一个对象的状态发生变化时,其它具有依赖关系的对象可以自动地被通知和更新。
eg:NSNotification、KVO
3.抽象工厂
提供一个接口,用于创建与某些对象相关或依赖于某些对象的类家族,而又不需要指定它们的具体类。
eg:Foundation的NSString
、NSData、NSDictionary、NSSet、和NSArray –>NSMutableString、NSMutableData、NSMutableDictionary、NSMutableSet、和NSMutableArray
4.原型模式
用原型实例指定创建对象的种类,并且通过拷贝这些原型创建新的对象。
eg:对象的深浅复制
5.适配器模式
将一个类的接口转换成另外一个客户希望的接口。Adapter 模式使得原本由于接口不兼容而不能一起工作的那些类可以一起工作。
eg:UITableView二次封装减少代码量
6.代理模式
为其他对象提供一种代理以控制对这个对象的访问。
eg:delegate,protocol
7.中介者模式
用一个中介对象来封装一系列的对象交互。中介者使各对象不需要显式地相互引用,从而使其耦合松散,而且可以独立地改变它们之间的交互。
eg:组件化 Mediator
8.MVC
iOS 开发中,MVC(Model View Controller)是构建iOS App的标准模式,是苹果推荐的一个用来组织代码的权威范式。Apple甚至是这么说的。在MVC下,所有的对象被归类为一个Model,一个View,和一个Controller。( Massive View Controller )
9.MVVM
MVC引申出来一种维护性较强、耦合性低的新的架构MVVM(Model View View-Mode),MVVM正式规范了视图和控制器紧耦合的性质,并引入新的组件。
10.MVP
MVP 即 Modal View Presenter
二.数据结构
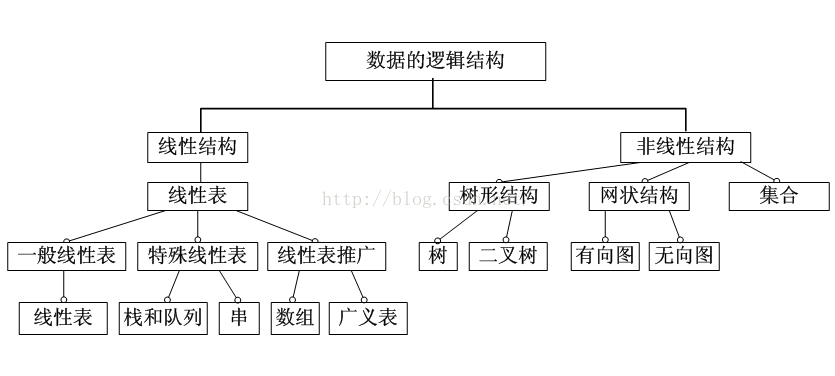
1.数组:按序排列的同类数据元素的集合称为数组
2.栈:只能在某一端插入和删除的特殊线性表
3.队列:一种特殊的线性表,它只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作
4.链表:一种物理存储单元上非连续、非顺序的存储结构,它既可以表示线性结构,也可以用于表示非线性结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的. 每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。
5.树:包含n(n>0)个结点的有穷集合K,且在K中定义了一个关系N,N满足 以下条件:
(1)有且仅有一个结点 K0,他对于关系N来说没有前驱,称K0为树的根结点。简称为根(root)。
(2)除K0外,K中的每个结点,对于关系N来说有且仅有一个前驱。
(3)K中各结点,对关系N来说可以有m个后继(m>=0)。
6.图:由结点的有穷集合V和边的集合E组成
7.堆:堆是一种特殊的树形数据结构,每个结点都有一个值。通常我们所说的堆的数据结构,是指二叉堆。堆的特点是根结点的值最小(或最大),且根结点的两个子树也是一个堆
8.哈希表(Hash table) : 哈希表(Hash Table)也叫散列表,是根据关键码值(Key Value)而直接进行访问的数据结构。它通过把关键码值映射到哈希表中的一个位置来访问记录,以加快查找的速度。这个映射函数就做散列函数,存放记录的数组叫做散列表。
哈希冲突
哈希冲突是指不同的输入数据经过哈希算法处理后产生相同的哈希值。哈希冲突可能导致数据的不完整性和正确性问题。常见的哈希冲突解决方法包括以下几种:
- 开放定址法(Open Addressing): 当发生哈希冲突时,采用一定的规则在哈希表中查找下一个空的位置来存放数据,常见的方法包括线性探测、二次探测和双重散列等。
- 链地址法(Chaining): 将哈希表中的每个位置设置为链表头指针,当发生哈希冲突时,将新数据插入到对应位置的链表中,实现链式存储。
- 再哈希(Rehashing): 当发生哈希冲突时,重新计算哈希值并找到一个空的位置来存放数据,可以采用不同的哈希函数或者哈希函数参数。
- 哈希表扩容(Resize): 当哈希表中的元素数量超过一定阈值时,对哈希表进行扩容,重新计算哈希值并将数据重新插入到新的哈希表中,减少哈希冲突的发生。
链表拓展
单向链表(Singly Linked List): 单向链表中的节点包含两部分信息,一部分是存储的数据(值或者键值对),另一部分是指向下一个节点的指针。每个节点只有一个指针,指向下一个节点,最后一个节点的指针为空(NULL)。单向链表只能从头节点开始依次访问到尾节点,无法从尾节点反向访问到头节点。
双向链表(Doubly Linked List): 双向链表中的节点包含三部分信息,分别是存储的数据、指向前一个节点的指针和指向后一个节点的指针。每个节点有两个指针,分别指向前一个节点和后一个节点,头节点的前指针为空(NULL),尾节点的后指针为空(NULL)。双向链表可以从头节点或尾节点开始向前或向后遍历,具有双向遍历的特性。
循环链表(Circular Linked List): 循环链表是一种特殊形式的链表,它与普通链表的区别在于,尾节点的指针不为空(NULL),而是指向头节点,形成一个闭环的结构。循环链表可以从任意节点开始遍历,当遍历到尾节点时会绕回到头节点继续遍历,因此可以无限循环访问。
带头节点链表(Head Linked List): 带头节点链表是在链表头部添加一个空节点作为头节点的链表,头节点不存储数据,只作为链表的起始标志。带头节点链表的优点是可以统一处理头节点和其他节点的操作,使得链表操作更加统一。
稀疏链表(Sparse Linked List): 稀疏链表是一种特殊用途的链表,主要用于表示稀疏矩阵。稀疏矩阵中大部分元素为零,为节省存储空间,可以使用稀疏链表来表示非零元素的位置和值,从而减少存储空间的占用。
链表结构
链表中的节点通常可以表示为:���,�����,����Key,Valu**e,Nex**t,其中:
- Key:键,用于确定节点在哈希表中的位置。
- Value:值,存储在节点中的具体数据。
- Next:指向下一个节点的指针,用于实现链表的连接。
通过链表的这种结构,可以实现在哈希表中存储多个键值对,并且能够有效处理哈希冲突,保证数据的存储和查找效率。
三.算法
LRU算法
LRU(Least Recently Used,最近最少使用)算法是一种常用的缓存淘汰策略,它根据数据的使用情况来决定哪些数据应该被淘汰,从而保留最近使用频率较高的数据,提高缓存命中率。下面是一个简单的LRU算法设计:
- 使用双向链表和哈希表:
- 双向链表用于存储缓存数据,最近访问过的数据放在链表头部,最久未访问的数据放在链表尾部;
- 哈希表用于快速查找数据在链表中的位置。
- 数据结构设计:
- 双向链表节点包括键、值以及前后指针;
- 哈希表的键为缓存数据的键,值为对应的双向链表节点。
- 算法流程:
- 当需要访问缓存数据时,先在哈希表中查找该数据是否存在;
- 如果存在,则将对应的双向链表节点移动到链表头部,并更新哈希表中的位置;
- 如果不存在,需要将数据加载到缓存中:
- 如果缓存未满,则直接将新数据插入到链表头部,并在哈希表中添加对应的键值对;
- 如果缓存已满,则需要淘汰最久未访问的数据(链表尾部节点),然后将新数据插入到链表头部,并更新哈希表中的位置。
- 淘汰策略:
- 每次访问缓存数据时,如果缓存已满,需要淘汰链表尾部的节点,即最近最少使用的数据;
- 淘汰时,从链表尾部删除节点,并在哈希表中删除对应的键值对。
四.应用的生命周期
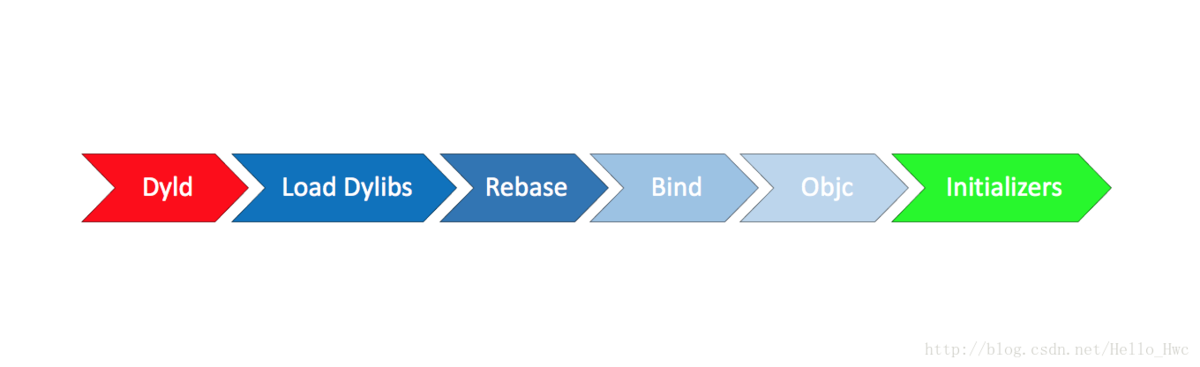
1.main()之前经历什么:
1.动态库链接库 dylib
2.ImageLoader加载可执行文件, 里边是被编译过的符号,代码等
3.runtime与+load
2.main()之后:
1.执行AppDelegate的代理方法,主要是didFinishLaunchingWithOptions
2.初始化Window,初始化基础的ViewController结构(一般是UINavigationController+UITabViewController)
3.获取数据(Local DB/Network),展示给用户。
3.启动优化思路:
能延迟初始化的尽量延迟初始化,不能延迟初始化的尽量放到后台初始化。
三方SDK初始化,比如Crash统计; 像分享之类的,可以等到第一次调用再出初始化。
初始化某些基础服务,比如WatchDog,远程参数。
启动相关日志,日志往往涉及到DB操作,一定要放到后台去做
业务方初始化,这个交由每个业务自己去控制初始化时间。
4.内存中的5大区
- 栈区(stack):由编译器自动分配释放 ,存放函数的参数值,局部变量的值等。其 操作方式类似于数据结构中的栈。
- 堆区(heap):一般由程序员分配释放, 若程序员不释放,程序结束时可能由OS回收 。注意它与数据结构中的堆是两回事,分配方式倒是类似于链表。
- 全局区(静态区)(static):全局变量和静态变量的存储是放在一块的,初始化的 全局变量和静态变量在一块区域, 未初始化的全局变量和未初始化的静态变量在相邻的另一块区域。 - 程序结束后由系统释放。
- 文字常量区:常量字符串就是放在这里的。 程序结束后由系统释放。
- 程序代码区:存放函数体的二进制代码。
五. OC语言设计原理
1. synthesize , dynamic
@synthesize的语义是如果你没有手动实现setter方法和getter方法,那么编译器会自动为你加上这两个方法。
@dynamic告诉编译器:属性的setter与getter方法由用户自己实现,不自动生成。(当然对于readonly的属性只需提供getter即可)。编译时没问题,运行时才执行相应的方法,这就是所谓的动态绑定。
2.+(void)load和+(void)initialize
- 当类被引用进项目的时候就会执行load函数(在main函数开始执行之前),与这个类是否被用到无关,每个类的load函数只会自动调用一次
- initialize在类或者其子类的第一个方法被调用前调用
3.各种关键字
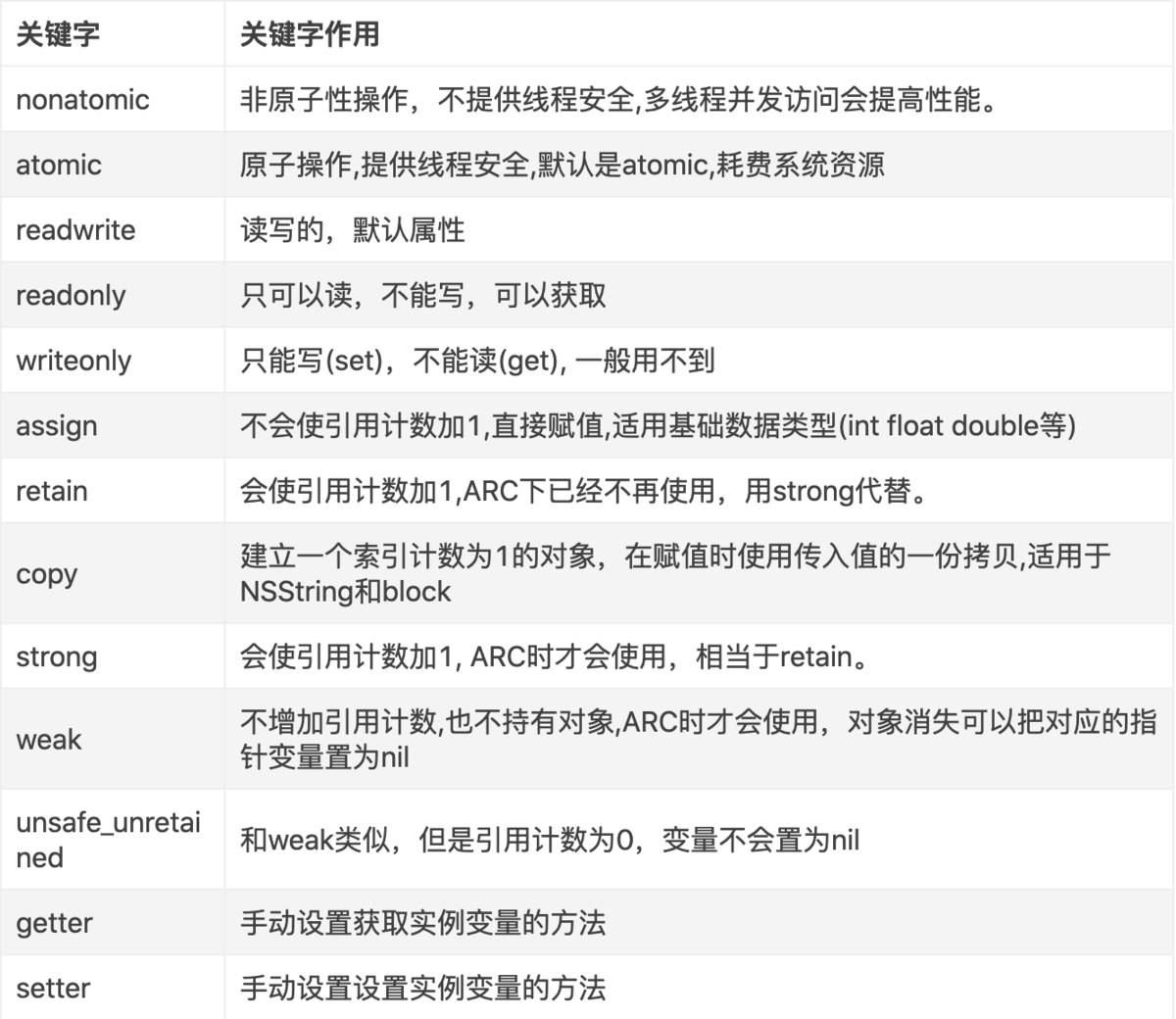
atomic : 只能实现读写的线程安全,并不能保证该属性本身的线程安全.
Weak: Weak表是一个hash(哈希)表,然后里面的key是指向对象的地址,Value是Weak指针的地址(这个地址的值是所指对象指针的地址)的数组
Copy: setter方法进行Copy操作,与retain处理流程一样,先旧值release,再Copy出新的对象,retainCount为1
unsafe_unretained : 修饰的指针纯粹只是指向对象,没有任何额外的操作
Assign: 简单赋值,不改变引用计数
4. ARC和MRC,AutoRelease
ARC: Automatic Reference Counting 自动引用,完全消除了手动管理内存的烦琐,编译器会自动在适当的地方插入适当的retain、release、autorelease语句
MRC: 手动管理内存(retain, release, autorelease,不多说) 持有对象,retain+1 ,引用计数加1, 释放对象:release -1, 引用计数减1,当引用计数为0时,会自动释放内存
经过分析,
AutoreleasePool的内存结构如上图所示,特点如下:
- 自动释放池是一个栈的结构,是一个以
AutoreleasePoolPage为结点的双向链表,根据需要来动态添加或删除页面。- 每一页
AutoreleasePoolPage的大小为4096字节,地址从低到高依次存储page自身成员、哨兵、对象指针。其中,自身成员占用56字节,且哨兵作为对象指针的边界,在释放池里只会有一个,因此:
- 第一页,内部存放:
page成员+1个哨兵+504个对象指针。- 其它页,内部存放:
page成员+505个对象指针。- 已存满的页面被标记为
full page,当前正在操作的页被标记为hot page。AutoreleasePoolPage继承自AutoreleasePoolPageData,内部成员情况如下:
magic:用来校验AutoreleasePoolPage的结构是否完整。next:下次新添加的autoreleased对象的位置,初始化时指向begin()。thread:当前线程,说明自动释放池和线程有关联。parent:指向父节点,即上一个页面,第一个页面的parent值为nil。child:指向子节点,即下一个页面,最后一个页面的child值为nil。depth:表示页面深度,从0开始,往后递增1。hiwat:即high water mark,表示最大入栈数量标记
Runloop和Autorelease Pool联系:
在没有手加Autorelease Pool的情况下,Autorelease对象是在当前的runloop迭代结束时释放的
1 | 根据苹果官方文档中对 NSRunLoop 的描述,我们可以知道每一个线程,包括主线程,都会拥有一个专属的 NSRunLoop 对象,并且会在有需要的时候自动创建。子线程的runloop需要自己手动创建,如果子线程的runloop没有任何事件,runloop会马上退出。(曾经我在写异步网络请求时想利用runloop来暂停线程来执行回调,但是由于没有添加任何事件源,导致runloop马上结束。网络请求失败)如果在每个 event loop 开始前,系统会自动创建一个 autoreleasepool ,并在 event loop 结束时 drain 。我们上面提到的场景 1 中创建的 autoreleased 对象就是被系统添加到了这个自动创建的 autoreleasepool 中,并在这个 autoreleasepool 被 drain 时得到释放。另外,NSAutoreleasePool 中还提到,每一个线程都会维护自己的 autoreleasepool 堆栈。换句话说 autoreleasepool 是与线程紧密相关的,每一个 autoreleasepool 只对应一个线程。 |
5. Category和Extension
Category :
2
3
4
5
6
7
8
9
> const char *name;//类的名字 主类名字
> classref_t cls;//类
> struct method_list_t *instanceMethods;//实例方法的列表
> struct method_list_t *classMethods;//类方法的列表
> struct protocol_list_t *protocols;//所有协议的列表
> struct property_list_t *instanceProperties;//添加的所有属性
> } category_t;
>
>
作用:可以在不修改原来类的基础上,为一个类扩展方法 . category_t 中的方法列表是插入到主类的方法列表前面(类似利用链表中的 next 指针来进行插入),所以这里 Category 中实现的方法并不会真正的覆盖掉主类中的方法,只是将 Category 的方法插到方法列表的前面去了.
2
3
4
5
6
7
8
9
10
11
> @property (nonatomic,copy ) NSString *name;
> @end
> @implementation NSObject (Extension)
> - (void)setName:(NSString *)name {
> objc_setAssociatedObject(self, @selector(name), name, OBJC_ASSOCIATION_COPY_NONATOMIC);
> }
> - (NSString *)name {
> return objc_getAssociatedObject(self,@selector(name));
> }
>
>
category是在运行时添加到类中,因为类的内存已经确定所以无法添加实例变量,但是可以添加@property生成setter,getter (实质还是方法). 注:
关联对象以哈希表的格式,存储在一个全局的单例中。
Extension :
类扩展与分类相比只少了分类的名称,所以称之为“匿名分类” .
extension 可以添加方法和属性(包括实例变量), 因为它是编译时被添加到类中.
注意:
在Objective-C中,如果多个Category中的方法重名,最终的方法实现会按照编译器的编译顺序来确定。具体来说,最后编译的Category会覆盖之前编译的同名方法。
6.@property和实例变量
- @property是是声明属性的语法
- @property用在声明文件中告诉编译器声明成员变量的的访问器(getter/setter)方法
- 使用@property的好处是:免去我们手工书写getter和setter方法繁琐的代码
7. id和instancetype的区别
id:
id是一个通用的指针类型,可以指向任何 Objective-C 对象。使用
id声明的对象可以接收任何消息,编译器不会对其进行类型检查,因此在编译时无法确定对象的具体类型。由于
id是一个通用类型,它不会受到编译时类型检查的限制,因此可以用来处理多态性的对象或者未知类型的对象。
instancetype:
instancetype是一个在编译时进行类型检查的关键字,用于声明返回当前类实例的方法。- 使用
instancetype声明的方法,返回的对象类型会与调用该方法的类相匹配,编译器会确保返回的对象是当前类的实例或者其子类的实例。 instancetype主要用于声明工厂方法(Factory Method),用于创建并返回当前类的实例。
8.内存管理和循环引用
- 内存管理原则:
- 在 Objective-C 和 Swift 中,都使用了自动引用计数(ARC)来管理内存,避免手动管理内存带来的问题。
- ARC 会自动追踪对象的引用关系,并在引用计数为零时自动释放对象占用的内存。
- 强引用(Strong Reference):
- 强引用是最常见的引用方式,指的是对象之间的强关联关系,一个对象强引用另一个对象时,会增加被引用对象的引用计数。
- 当强引用的循环链中出现闭环(循环引用)时,对象之间无法被释放,导致内存泄漏。
- 循环引用的产生:
- 在闭包中捕获
self时容易产生循环引用,特别是在使用[weak self]或[unowned self]时要小心处理。 - 如果闭包中使用了强引用的
self,而self又持有该闭包的强引用,就会形成循环引用。
- 在闭包中捕获
- 解决循环引用:
- 使用
[weak self]或[unowned self]来避免对self的强引用,从而打破循环引用。 - 对于可能造成循环引用的情况,应该谨慎设计代码逻辑,避免形成循环引用。
- 使用
- 使用捕获列表:
- 在闭包中使用捕获列表可以明确指定对对象的引用类型,如
[weak self]或[unowned self]。 - 捕获列表可以有效地解决闭包中可能出现的循环引用问题。
- 在闭包中使用捕获列表可以明确指定对对象的引用类型,如
- 使用 Instruments 进行内存检测:
- 在开发过程中,可以使用 Xcode 的 Instruments 工具进行内存检测和分析,帮助发现和解决内存泄漏等问题。
虽然 ARC(Automatic Reference Counting,自动引用计数)在大多数情况下能够很好地管理内存,但有一些特殊情况下 ARC 处理不了,需要手动进行内存管理或者采取其他解决方案。以下是一些 ARC 处理不了的情况:
- 循环引用(Circular Reference):
- ARC 虽然可以自动释放对象,但当对象之间形成循环引用时,会导致对象无法释放而产生内存泄漏。这时需要使用弱引用(
weak)或者无主引用(unowned)来打破循环引用。
- ARC 虽然可以自动释放对象,但当对象之间形成循环引用时,会导致对象无法释放而产生内存泄漏。这时需要使用弱引用(
- Core Foundation 对象(Core Foundation Objects):
- ARC 只负责 Objective-C 对象的内存管理,对于 Core Foundation 对象(如 CFStringRef、CFArrayRef 等)需要手动管理内存,使用 Core Foundation 的内存管理函数(如 CFRetain 和 CFRelease)来管理内存。
- Cocoa API 的一些方法(Certain Cocoa API Methods):
- 有些 Cocoa API 方法返回的对象不受 ARC 管理,需要手动管理内存,通常使用
autorelease来延迟释放对象。
- 有些 Cocoa API 方法返回的对象不受 ARC 管理,需要手动管理内存,通常使用
- 底层数据结构(Low-Level Data Structures):
- 对于底层的数据结构,如操作指针、内存缓存等,需要特殊处理,避免内存泄漏或者野指针问题。
- Core Graphics 和 Core Animation 对象(Core Graphics and Core Animation Objects):
- 对于 Core Graphics 和 Core Animation 相关的对象,需要注意内存管理,特别是在使用 C 语言接口时,需要手动释放对象。
- 跨线程操作(Cross-Thread Operations):
- 在多线程环境下,如果不正确地处理对象的内存管理,可能会导致线程安全问题和内存泄漏。
- Block 中的对象引用(Object References in Blocks):
- 在使用 Block 时,需要小心处理对象的引用关系,避免循环引用和内存泄漏。
- 自定义的内存管理逻辑(Custom Memory Management Logic):
- 如果在项目中使用了自定义的内存管理逻辑,可能会与 ARC 的自动内存管理产生冲突,需要谨慎处理。
野指针:访问无效内存导致崩溃
六. Swift语言设计原理
1.swift中高阶函数map、flatMap、filter、reduce
map:可以对数组中的每一个元素做一次处理.
flatMap: 对元素进行操作同时 会解包和展开二维数组,且去除nil.
filer:过滤,可以对数组中的元素按照某种规则进行一次过滤.
reduce:计算,可以对数组的元素进行计算.
2.结构体和类对比
Swift 中结构体和类有很多共同点。两者都可以:
- 定义属性用于存储值
- 定义方法用于提供功能
- 定义下标操作用于通过下标语法访问它们的值
- 定义构造器用于设置初始值
- 通过扩展以增加默认实现之外的功能
- 遵循协议以提供某种标准功能
更多信息请参见 属性、方法、下标、构造过程、扩展 和 协议。
与结构体相比,类还有如下的附加功能:
- 继承允许一个类继承另一个类的特征
- 类型转换允许在运行时检查和解释一个类实例的类型
- 析构器允许一个类实例释放任何其所被分配的资源
- 引用计数允许对一个类的多次引用
3.值类型有哪些
结构体,枚举
Swift 中所有的基本类型:整数(integer)、浮点数(floating-point number)、布尔值(boolean)、字符串(string)、数组(array)和字典(dictionary),都是值类型,其底层也是使用结构体实现的.
4.copy on write
Swift 中的值类型,并不会在一开始赋值的时候就开辟新的内存空间,只有在需要改变这个值的时候才去开辟新的内存空间,以达到优化内存的目的.
标准库定义的集合,例如数组,字典和字符串,都对复制进行了优化以降低性能成本。新集合不会立即复制,而是跟原集合共享同一份内存,共享同样的元素。在集合的某个副本要被修改前,才会复制它的元素。而你在代码中看起来就像是立即发生了复制。
5.optiinal原理
2
3
4
5
> case some(T) //对于所有成功的情况,我们用case some,并且把成功的结果保存在associated value里;
> case none 对于所有错误的情况,我们用case none来表示;
> }
>
6.Swift中如何使用runtime
Swift代码中已经没有了Objective-C的运行时消息机制, 在代码编译时即确定了其实际调用的方法. 所以纯粹的Swift类和对象没有办法使用runtime, 更不存在method swizzling.
为了兼容Objective-C, 凡是继承NSObject的类都会保留其动态性, 依然遵循Objective-C的运行时消息机制, 因此可以通过runtime获取其属性和方法, 实现method swizzling.
7.闭包
为了优化,如果一个值不会被闭包改变,或者在闭包创建后不会改变,Swift 可能会改为捕获并保存一份对值的拷贝。
Swift 也会负责被捕获变量的所有内存管理工作,包括释放不再需要的变量。
8.作用域修饰符
open 和 public 级别可以让实体被同一模块源文件中的所有实体访问,在模块外也可以通过导入该模块来访问源文件里的所有实体。通常情况下,你会使用 open 或 public 级别来指定框架的外部接口。open 只能作用于类和类的成员,它和 public 的区别主要在于 open 限定的类和成员能够在模块外能被继承和重写.
internal 级别让实体被同一模块源文件中的任何实体访问,但是不能被模块外的实体访问。通常情况下,如果某个接口只在应用程序或框架内部使用,就可以将其设置为 internal 级别。
fileprivate 限制实体只能在其定义的文件内部访问。如果功能的部分实现细节只需要在文件内使用时,可以使用 fileprivate 来将其隐藏。
private 限制实体只能在其定义的作用域,以及同一文件内的 extension 访问。如果功能的部分细节只需要在当前作用域内使用时,可以使用 private 来将其隐藏。
9.Swift和OC对比
1 | 1.语法简洁性 |
七.iOS各种机制和原理
1.Runloop
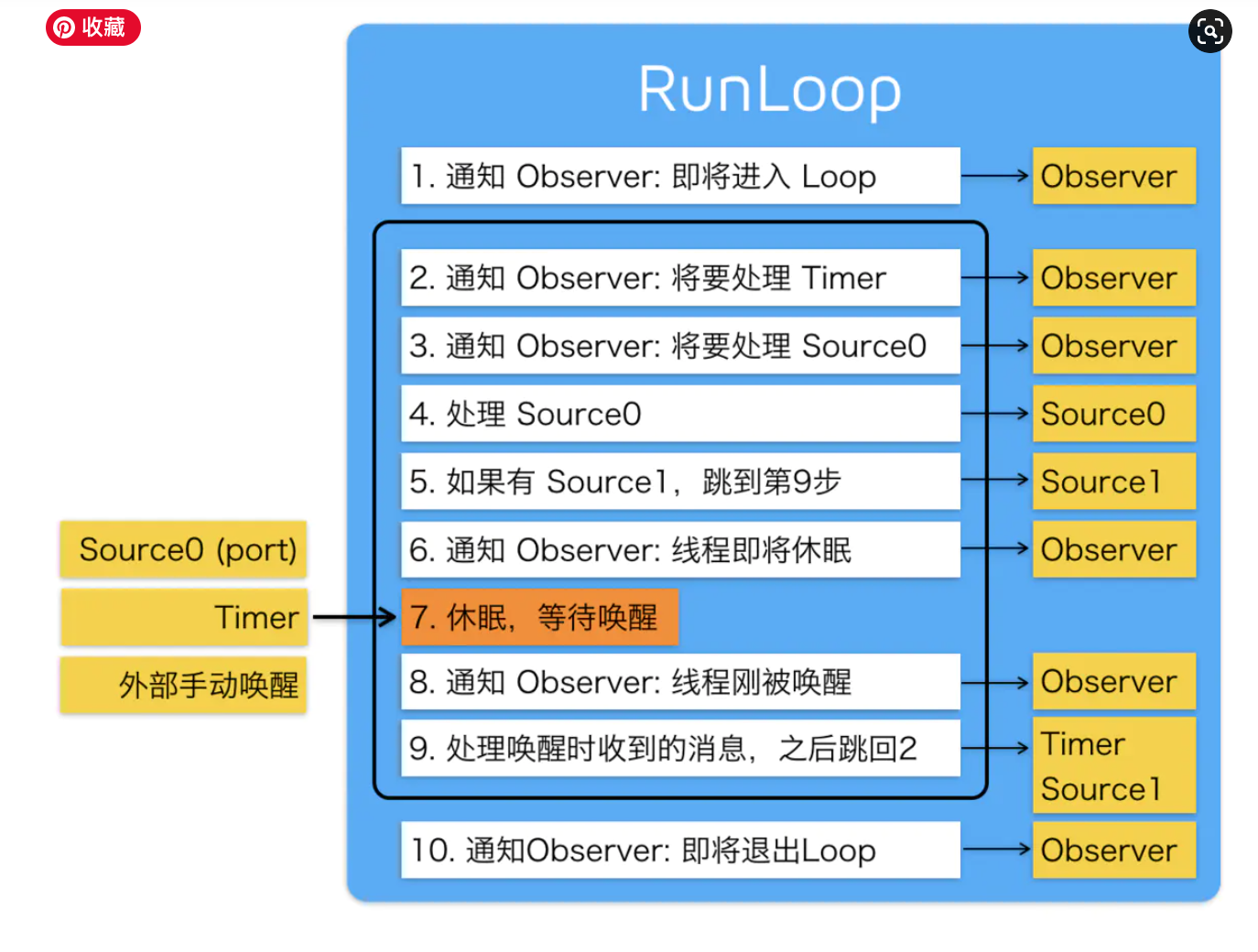
可以理解为字面意思:Run 表示运行,Loop 表示循环。结合在一起就是运行的循环的意思。哈哈,我更愿意翻译为『跑圈』。直观理解就像是不停的跑圈。
- RunLoop 实际上是一个对象,这个对象在循环中用来处理程序运行过程中出现的各种事件(比如说触摸事件、UI刷新事件、定时器事件、Selector事件),从而保持程序的持续运行。
- RunLoop 在没有事件处理的时候,会使线程进入睡眠模式,从而节省 CPU 资源,提高程序性能。
- Source0 是App内部事件,只包含一个函数指针回调,并不能主动触发事件,使用时,你需要先调用CFRunLoopSourceSignal(source),将这个source标记为待处理,然后手动调用CFRunLoopWakeUp(runloop)来唤醒RunLoop,让其处理这个事件。
- Source1 包含一个mach_port和一个函数回调指针。source1是基于port的,通过读取某个port上内核消息队列上的消息来决定执行的任务,然后再分发到sources0中处理的。source1只供系统使用,并不对开发者开放。
2.Runtime
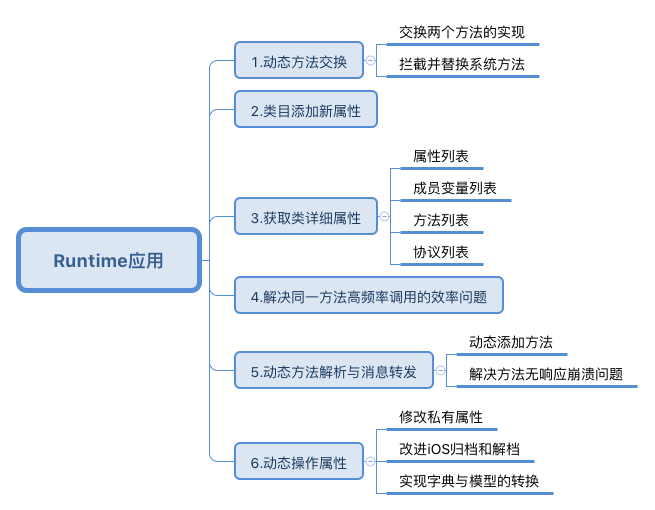
Runtime API提供的接口基本都是C语言的,源码由C\C++\汇编语言编写.
Objective-C成为动态性语言的基石.
- 动态方法解析 : 让你有机会提供一个函数实现
- 备用接收者 : 给你把这个消息转发给其他对象的机会
- 完整消息转发 :
-methodSignatureForSelector:消息获得函数的参数和返回值,如果返回了一个函数签名,Runtime就会创建一个NSInvocation对象并发送-forwardInvocation:消息给目标对象
3.dsym符号表
dSYM符号表是一个在苹果操作系统(macOS和iOS)中用于调试的文件格式。dSYM是“debugging symbol(调试符号)”的缩写
1 | <起始地址> <结束地址> <函数> [<文件名:行号>] |
1 | 苹果提供了一个名为"App Store Connect"的在线开发者平台,用于管理应用程序、测试人员、Crash日志和其他开发者相关的资源。开发者可以使用该平台来上传dSYM符号表文件以帮助苹果收集和分析应用程序的Crash日志。 |
dSYM 符号表
- 作用:
dSYM文件包含了应用程序的符号信息,包括类、方法、变量等的名称和地址信息,可以帮助调试工具将崩溃日志中的内存地址转换为具体的类和方法名,方便开发者定位问题。 - 生成方式: 在 Xcode 中构建应用程序时,会生成
.app文件和对应的dSYM文件。dSYM文件通常存储在应用程序的归档文件(Archive)中,或者可以通过 Xcode 的 Organizer 导出。 - 使用场景: 当应用程序发生崩溃或者异常时,收集到的崩溃日志中通常包含了内存地址、堆栈信息等。通过
dSYM文件,调试工具可以将内存地址转换为对应的类和方法名,使得开发者能够更准确地定位问题所在。 - 注意事项: 确保在发布应用程序时保留
dSYM文件,并在需要进行崩溃分析时提供给调试工具使用。
Bugly 的实现原理
Bugly 是一个专注于移动应用异常监控和实时崩溃分析的第三方服务,其实现原理主要包括以下几个方面:
- 异常捕获: Bugly SDK 集成到应用程序中,通过监控异常信号、崩溃日志等方式,实时捕获应用程序的异常情况。
- 崩溃信息采集: 当应用程序发生异常或者崩溃时,Bugly SDK会收集相关的崩溃信息,包括堆栈信息、设备信息、应用版本等。
- 崩溃日志上传: Bugly SDK将收集到的崩溃日志上传到 Bugly 服务器,供开发者分析和查看。
- 符号化: 在收到崩溃日志后,Bugly 服务器会使用相应的
dSYM文件对日志中的内存地址进行符号化,将内存地址转换为具体的类和方法名。 - 实时监控和分析: Bugly 提供实时的异常监控和崩溃分析服务,开发者可以通过 Bugly 后台实时查看应用程序的异常情况、崩溃日志以及分析报告,帮助定位和解决应用程序的问题。
4.NULL
标识 值 含义
NULL (void *)0 C指针的字面零值
nil (id)0 Objective-C对象的字面零值
Nil (Class)0 Objective-C类的字面零值
NSNull [NSNull null] 用来表示零值的单独的对象
5.静态库和动态库
动态库和静态库介绍
1
2
3
4首先静态库和动态库都是以二进制提供代码复用的代码库
静态库 常见的是 .a
动态库常见的是 .dll(windows),.dylib(mac),so(linux)
framework(in Apple): Framework 是Cocoa/Cocoa Touch程序中使用的一种资源打包方式,可以将代码文件、头文件、资源文件、说明文档等集中在一起,方便开发者使用。也就是说我们的 framework其实是资源打包的方式,和静态库动态库的本质是没有关系的静态库和动态库的区别
1
2
3
4静态库: 链接时会被完整的复制到可执行文件中,所以如果两个程序都用了某个静态库,那么每个二进制可执行文件里面其实都含有这份静态库的代码
动态库: 链接时不复制,在程序启动后用dyld加载,然后再决议符号,所以理论上动态库只用存在一份,好多个程序都可以动态链接到这个动态库上面,达到了节省内存(不是磁盘是内存中只有一份动态库),还有另外一个好处,由于动态库并不绑定到可执行程序上,所以我们想升级这个动态库就很容易,windows和linux上面一般插件和模块机制都是这样实现的。
But我们的苹果爸爸在iOS平台上规定不允许存在动态库,并且所有的 IPA 都需要经过苹果爸爸的私钥加密后才能用,基本你用了动态库也会因为签名不对无法加载,(越狱和非 APP store 除外)。于是就把开发者自己开发动态库掐死在幻想中。
直到有一天,苹果爸爸的iOS升级到了8,iOS出现了APP Extension,swift编程语言也诞生了,由于iOS主APP需要和Extension共享代码,Swift语言的机制也只能有动态库,于是苹果爸爸尴尬了,不过这难不倒我们的苹果爸爸,毕竟我是爸爸,规则是我来定,我想怎样就怎样,于是提出了一个概念Embedded Framework,这种动态库允许APP和APP Extension共享代码,但是这份动态库的生命被限定在一个APP进程内。简单点可以理解为被阉割的动态库。
6.KVC 、KVO
kvc:使用字符串直接访问对象的属性,或者给对象属性赋值
kvo:键值观察机制,它提供了观察对象属性变化的方法
kvc底层实现 :
当一个对象调用setValue方法时,方法内部会做以下操作:
1.检查是否存在相应key的set方法,如果存在,就调用set方法
2.如果set方法不存在,就会查找与key相同名称并且带下划线的成员属性,如果有,则直接给成员属性赋值
3.如果没有找到_key,就会查找相同名称的属性key,比如_iskey,iskey,如果有就直接赋值
4.如果还没找到,则调用valueForUndefinedKey:和setValue:forUndefinedKey:方法
如果开发者想让这个类禁用KVC,那么重写+ (BOOL)accessInstanceVariablesDirectly方法让其返回NO即可,这样的话如果KVC没有找到set:属性名时,会直接用setValue:forUndefinedKey:方法。
KVO的底层实现 :
kvo基于runtime机制实现
使用了isa混写(isa-swizzling),当一个对象(假设是person对象,person的类是MyPerson)的属性值(假设person的age)被观察时(addObserver:),系统会自动生成一个类,继承自MyPerson,NSKVONotifying_MyPerson,打印这个子类可以看到内部也有一个 setName:方法 还重写了 class 和 dealloc 方法 , _isKVOA
官方解释:当某个类的对象一次被观察时,系统就会在运行时动态的创建该类的一个派生类(子类)
在这个类的setAge方法里面,调用
2
3
4
> [self setAge:age]
> [self didChangeValueForKey:@"age"]
>
>
而这两个方法内部会主动调用监听者内部的- (void)observeValueForKeyPath 这个方法。
7.Notification
NSNotificationCenter内部保存了两张(链)表:一张用户保存添加观察者时传入了NotificationName的情况,一种用户保存添加观察者时没有传入NoficationName的情况
Named Table
在named table中,NotificationName作为表的key,但因注册观察者的时可传入一个object参数用于接收指定对象发出的通知,并且一个通知可注册多个观察者,所以还需要一张表来保存object和observer的对应关系。这张表以object为key,observer为value。
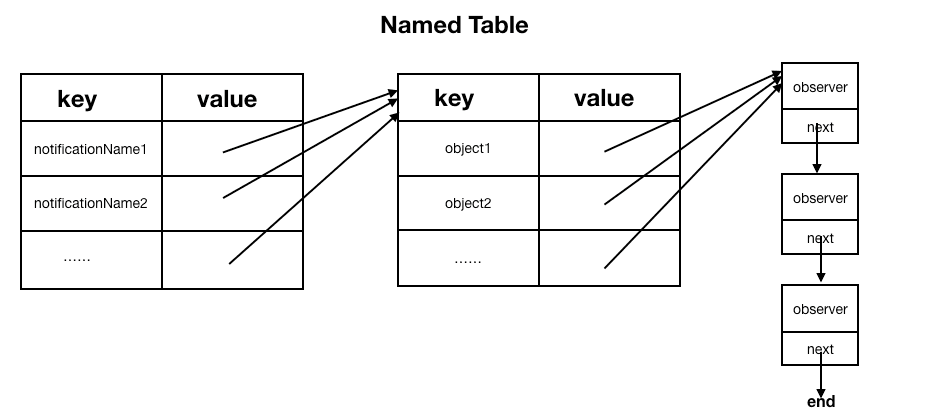
named table最终的数据结构如上图所示:
外层是一个table,以通知名称NotificationName为key,其value为一个table(简称内层table)。
内层table以object为key,其value为一个链表,用来保存所有的观察者。
Nameless Table
Nameless Table比Named Table要简单很多,因为没有NotificationName作为key,直接用object作为key。相较于Named Table要少一层table嵌套。
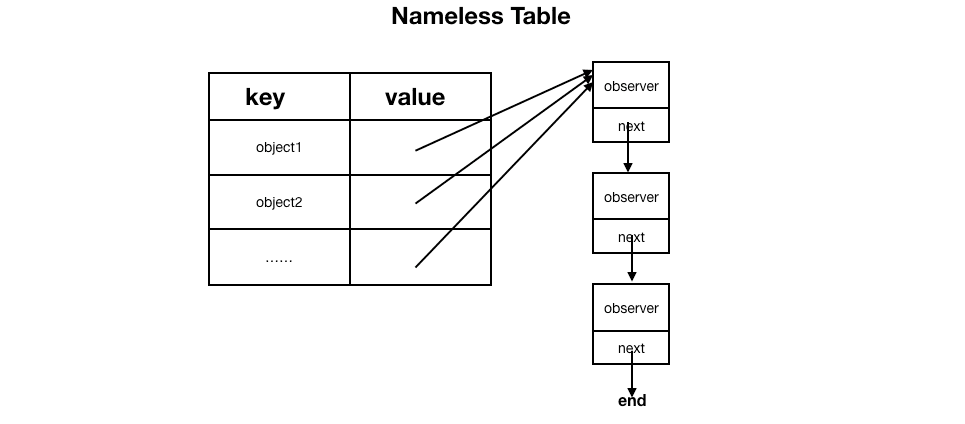
wildcard
wildcard是链表的数据结构,如果在注册观察者时既没有传入NotificationName,也没有传入object,就会添加到wildcard的链表中。注册到这里的观察者能接收到 所有的系统通知。
添加观察者流程
有了上面基本的结构关系,再来看添加过程就会很简单。在初始化NotificationCenter时会创建一个对象,这个对象里保存了Named Table、Nameless Table、wildcard和一些其它信息。所有注册观察者的操作最后都会调用addObserver:selector:name:object:。
- 首先会根据传入的参数实例化一个Observation,Observation对象保存了观察者对象,接收到通知观察者所执行的方法,以及下一个Observation对象的地址。
- 根据是否传入NotificationName选择操作Named Table还是Nameless Table。
- 若传入了NotificationName,则会以NotificationName为key去查找对应的Value,若找到value,则取出对应的value;若未找到对应的value,则新建一个table,然后将这个table以NotificationName为key添加到Named Table中。
- 若在保存Observation的table中,以object为key取对应的链表。若找到了则直接在链接末尾插入之前实例化好的Observation;若未找到则以之前实例化好的Observation对象作为头节点插入进去。
没有传入NotificationName的情况和上面的过程类似,只不过是直接根据对应的object为key去找对应的链表而已。如果既没有传入NotificationName也没有传入object,则这个观察者会添加到wildcard链表中。
发送通知流程
发送通知一般调用postNotificationName:object:userInfo:来实现,内部会根据传入的参数实例化一个NSNotification对象,包含name、object、userinfo等信息。
发送通知的流程总体来说是根据NotificationName和object找到对应的链表,然后遍历整个链表,给每个Observation节点中保存的oberver发送对应的SEL消息。
- 首先会创建一个数组observerArray用来保存需要通知的observer。
- 遍历wildcard链表,将observer添加到observerArray数组中。
- 若存在object,在nameless table中找到以object为key的链表,然后遍历找到的链表,将observer添加到observerArray数组中。
- 若存在NotificationName,在named table中以NotificationName为key找到对应的table,然后再在找到的table中以object为key找到对应的链表,遍历链表,将observer添加到observerArray数组中。如果object不为nil,则以nil为key找到对应的链表,遍历链表,将observer添加到observerArray数组中。
- 至此所有关于当前通知的observer(wildcard+nameless+named)都已经加入到了数组observerArray中。遍历observerArray数组,取出其中的observer节点(包含了观察者对象和selector),调用形式如下:
1 | [o->observer performSelector: o->selector withObject: notification]; |
这种处理通知的方式也就能说明,发送通知的线程和接收通知的线程是同一线程。
8.多线程
在 iOS 中其实目前有 4 套多线程方案,他们分别是:
- Pthreads
- NSThread
- GCD
- NSOperation & NSOperationQueue
1 | pthread_t thread; |
1 | 方式一: |
GCD
- GCD 简介
- GCD 任务和队列
- GCD 的使用步骤
- GCD 的基本使用(六种组合不同区别,队列嵌套情况区别,相互关系形象理解)
- GCD 线程间的通信
- GCD 的其他方法(栅栏方法:dispatch_barrier_async、延时执行方法:dispatch_after、一次性代码(只执行一次):dispatch_once、快速迭代方法:dispatch_apply、队列组:dispatch_group、信号量:dispatch_semaphore)
GCD 栅栏方法:dispatch_barrier_async
dispatch_barrier_async 方法会等待前边追加到并发队列中的任务全部执行完毕之后,再将指定的任务追加到该异步队列中
1 | /** |
dispatch_after
1 | /** |
dispatch_once
1 | /** |
dispatch_apply
dispatch_apply 按照指定的次数将指定的任务追加到指定的队列中,并等待全部队列执行结束
1 | /** |
dispatch_group,dispatch_group_notify
1 | /** |
NSOperation和NSOperationQueue
NSOperation 是苹果公司对 GCD 的封装,完全面向对象,所以使用起来更好理解。 大家可以看到 NSOperation 和 NSOperationQueue 分别对应 GCD 的 任务 和 队列 。操作步骤也很好理解:
- 将要执行的任务封装到一个
NSOperation对象中。 - 将此任务添加到一个
NSOperationQueue对象中。
1 | //1.任务一:下载图片 |
队列:用于存放任务。一共有两种队列, 串行队列 和 并行队列。
串行队列 中的任务会根据队列的定义 FIFO 的执行,一个接一个的先进先出的进行执行。
放到串行队列的任务,GCD 会
FIFO(先进先出)地取出来一个,执行一个,然后取下一个,这样一个一个的执行。主队列:这是一个特殊的
串行队列。什么是主队列,大家都知道吧,它用于刷新 UI,任何需要刷新 UI 的工作都要在主队列执行,所以一般耗时的任务都要放到别的线程执行。任务:即操作,你想要干什么,说白了就是一段代码,在 GCD 中就是一个 Block,所以添加任务十分方便。
| 同步执行 | 异步执行 | |
|---|---|---|
| 串行队列 | 当前线程,一个一个执行 | 其他线程,一个一个执行 |
| 并行队列 | 当前线程,一个一个执行 | 开很多线程,一起执行 |
任务:
计算机工作的基本工作单元,它由控制程序处理的一个或者多个指令序列。
线程:
是 操作系统 能够进行运算调度的最小单位。它被包含在进程中,是进程中实际运作单位。
一条线程:指的是进程中某一单一顺序的控制流,
一个进程可以并发多个线程,每条线程执行不同的任务。
小总结:线程是任务实际运作单位。(任务需要被放入线程中,才能执行)
队列:
数据结构,拥有先进先出的特点。是计算机中,用于存放任务的基本单位,分为串行队列和并行队列(GCD)。
队列与线程,就是两个不同的对象,其处理的业务逻辑本质就不一样。一个是执行任务(线程),一个是存储并分发任务(队列)
死锁: 主队列中追加的同步任务 和 主线程本身的任务 两者之间相互等待,阻塞了 『主队列』,最终造成了主队列所在的线程(主线程)死锁问题
- 进程(Process):
- 进程是计算机中正在运行的程序的实例,每个进程都有自己的内存空间和系统资源,是操作系统进行资源分配和管理的基本单位。
- 每个进程都可以包含一个或多个线程,各个进程之间是相互独立的,彼此不会共享内存空间。
- 线程(Thread):
- 线程是进程中的执行单元,一个进程可以包含多个线程,各个线程共享相同的内存空间和系统资源,但具有独立的执行路径。
- 多线程可以实现并发执行,提高程序的运行效率和响应速度。
- 队列(Queue):
- 队列是一种数据结构,用于存储和管理数据元素,遵循先进先出(FIFO)或者后进先出(LIFO)原则。
- 队列常用于多线程编程中,用于线程之间的通信和数据传递,例如生产者消费者模型中的任务队列。
主要区别如下:
- 进程是程序执行的实例,具有独立的内存空间和系统资源;线程是进程中的执行单元,共享进程的内存空间和资源。
- 进程之间是相互独立的,各自有独立的内存空间;线程共享进程的内存空间,可以方便地进行数据共享和通信。
- 队列是一种数据结构,用于存储和管理数据元素,常用于多线程编程中的任务调度和数据传递。
总的来说,进程和线程是操作系统中的核心概念,用于实现程序的并发执行和资源管理;而队列是一种数据结构,在多线程编程中起到了重要的作用,用于线程间的通信和数据传递。
9.锁
我们在使用多线程的时候多个线程可能会访问同一块资源,这样就很容易引发数据错乱和数据安全等问题,这时候就需要我们保证每次只有一个线程访问这一块资源,锁 应运而生。
悲观锁:总是假设最坏的情况,认为竞争总是存在,每次拿数据的时候都认为会被修改,因此每次都会先上锁。其他线程阻塞等待释放锁。
乐观锁:总是假设最好的情况,认为竞争总是不存在,每次拿数据的时候都认为不会被修改,因此不会先上锁,在最后更新的时候比较数据有无更新,可通过版本号或CAS实现。悲观锁:用于写比较多的情况,避免了乐观锁不断重试从而降低性能
乐观锁:用于读比较多的情况,避免了不必要的加锁的开销
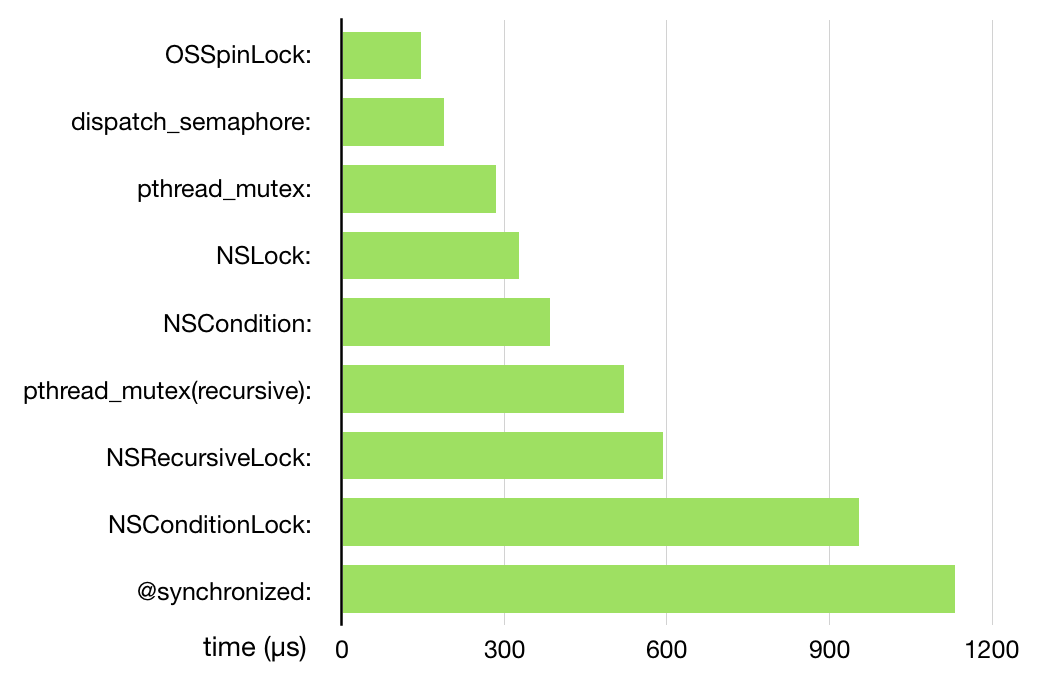
OSSpinLock
1 | __block OSSpinLock oslock = OS_SPINLOCK_INIT; |
dispatch_semaphore 信号量
1 | dispatch_semaphore_t signal = dispatch_semaphore_create(1); //传入值必须 >=0, 若传入为0则阻塞线程并等待timeout,时间到后会执行其后的语句 |
dispatch_semaphore_create(1): 传入值必须 >=0, 若传入为 0 则阻塞线程并等待timeout,时间到后会执行其后的语句
dispatch_semaphore_wait(signal, overTime):可以理解为 lock,会使得 signal 值 -1
dispatch_semaphore_signal(signal):可以理解为 unlock,会使得 signal 值 +1
pthread_mutex
1 | static pthread_mutex_t pLock; |
pthread_mutex(recursive)
1 | static pthread_mutex_t pLock; |
NSLock
lock、unlock:不多做解释,和上面一样
trylock:能加锁返回 YES 并执行加锁操作,相当于 lock,反之返回 NO
lockBeforeDate : 这个方法表示会在传入的时间内尝试加锁,若能加锁则执行加锁操作并返回 YES,反之返回 NO
NSCondition
wait:进入等待状态
waitUntilDate::让一个线程等待一定的时间
signal:唤醒一个等待的线程
broadcast:唤醒所有等待的线程
NSRecursiveLock
1 | NSLock *rLock = [NSLock new]; |
内部原理
NSRecursiveLock 之所以允许重复加锁而不会导致死锁,是因为它是一个递归锁(recursive lock)。递归锁允许同一个线程在持有锁的情况下多次加锁,而不会造成死锁的原因如下:
- 锁的持有计数:
NSRecursiveLock内部维护了一个锁的持有计数(lock count),每次成功调用lock方法时,计数会加一;每次成功调用unlock方法时,计数会减一。只有当锁的持有计数为零时,其他线程才能获得锁。 - 同一线程的锁重入: 当同一个线程再次调用
lock方法时,如果该线程已经持有了该锁(即锁的持有计数大于零),则锁的持有计数会增加,但并不会造成死锁。这样,同一线程可以在多个嵌套层次中重复获取和释放锁,保证了线程内部逻辑的正确性。
@synchronized
内部原理
1 | typedef struct SyncData { |
1 | //线程1 |
NSConditionLock
1 | NSConditionLock *cLock = [[NSConditionLock alloc] initWithCondition:0]; |
自旋锁 和 互斥锁的区别和实现原理
区别:
等待资源时的行为
:
- 自旋锁:当线程尝试获取锁但发现锁已被其他线程占用时,它会一直循环等待(自旋),直到锁被释放。这种方式会消耗 CPU 资源,适用于短时间内锁的占用情况。
- 互斥锁:当线程尝试获取锁但发现锁已被其他线程占用时,它会进入阻塞状态,等待锁被释放。在等待期间,线程不会占用 CPU 资源,适用于长时间内锁的占用情况。
实现原理:
- 自旋锁:
- 实现方式:自旋锁通过在循环中不断检查锁的状态来实现。当线程尝试获取锁时,它会反复检查锁的状态,直到获取到锁为止。
- 适用场景:自旋锁适用于对资源的占用时间较短,且并发竞争不激烈的情况。因为自旋锁会持续占用 CPU 资源,如果等待时间过长或竞争过于激烈,会导致性能下降。
- 互斥锁:
- 实现方式:互斥锁通过操作系统提供的原子操作和内核支持来实现。当线程尝试获取锁时,如果锁已被占用,线程会进入阻塞状态,直到锁被释放后才能继续执行。
- 适用场景:互斥锁适用于对资源的占用时间较长,或者并发竞争较激烈的情况。由于线程在等待时不会占用 CPU 资源,因此可以避免资源的浪费和性能下降。
- 自旋锁:
总的来说,自旋锁适用于短时间内锁的占用情况,并且适用于并发竞争不激烈的场景;而互斥锁适用于长时间内锁的占用情况,或者并发竞争较激烈的场景。选择哪种锁取决于实际的应用场景和对并发控制的需求。
@synchronized总结
objc_sync_exit流程和objc_sync_enter流程走的是一样的只不过一个是加锁一个是解锁@synchronized底层是链表查找、缓存查找以及递归,是非常耗内存以及性能的@synchronized底层封装了是一把递归锁,可以自动进行加锁解锁,这也是大家喜欢使用它的原因@synchronized中lockCount控制递归,而threadCount控制多线程@synchronized加锁的对象尽量不要为nil,不然起不到加锁的效果
10.Block和闭包
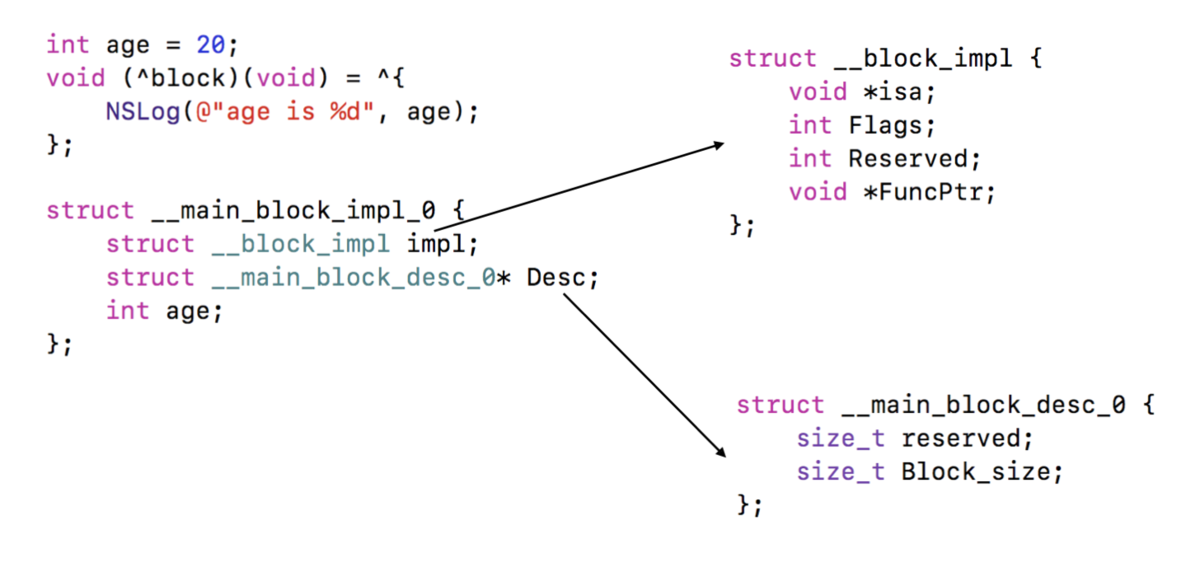
block 是一个封装了函数调用和局部变量的运行环境的结构体对象
只要是栈上的block都不会捕获变量。
只要是堆上的block 如果引用了外部的局部变量,会根据局部变量使用strong 还是用weak来决定是否强引用;Block修改外部变量
Soultion1:用static修饰或者改成全局变量
Soultion2:用block修饰或者改成全局变量
编译器会将block变量包装成一个对象,并且被Block强引用闭包 : 闭包是自包含的函数代码块,可以在代码中被传递和使用。Swift 中的闭包与 C 和 Objective-C 中的代码块(blocks)以及其他一些编程语言中的匿名函数(Lambdas)比较相似。
11.响应者链
3.1.事件的产生
- 发生触摸事件后,系统会将该事件加入到一个由UIApplication管理的事件队列中,为什么是队列而不是栈?因为队列的特点是FIFO,即先进先出,先产生的事件先处理才符合常理,所以把事件添加到队列。
- UIApplication会从事件队列中取出最前面的事件,并将事件分发下去以便处理,通常,先发送事件给应用程序的主窗口(keyWindow)。
- 主窗口会在视图层次结构中找到一个最合适的视图来处理触摸事件,这也是整个事件处理过程的第一步。
找到合适的视图控件后,就会调用视图控件的touches方法来作具体的事件处理。
3.2.事件的传递
- 触摸事件的传递是从父控件传递到子控件
- 也就是UIApplication->window->寻找处理事件最合适的view
注 意: 如果父控件不能接受触摸事件,那么子控件就不可能接收到触摸事件
应用如何找到最合适的控件来处理事件?
- 1.首先判断主窗口(keyWindow)自己是否能接受触摸事件
- 2.判断触摸点是否在自己身上
- 3.子控件数组中从后往前遍历子控件,重复前面的两个步骤(所谓从后往前遍历子控件,就是首先查找子控件数组中最后一个元素,然后执行1、2步骤)
- 4.view,比如叫做fitView,那么会把这个事件交给这个fitView,再遍历这个fitView的子控件,直至没有更合适的view为止。
- 5.如果没有符合条件的子控件,那么就认为自己最合适处理这个事件,也就是自己是最合适的view。
UIView不能接收触摸事件的三种情况:
- 不允许交互:userInteractionEnabled = NO
- 隐藏:如果把父控件隐藏,那么子控件也会隐藏,隐藏的控件不能接受事件
- 透明度:如果设置一个控件的透明度<0.01,会直接影响子控件的透明度。alpha:0.0~0.01为透明。
产生触摸事件->UIApplication事件队列->[UIWindow hitTest:withEvent:]->返回更合适的view->[子控件 hitTest:withEvent:]->返回最合适的view
事件传递给窗口或控件的后,就调用hitTest:withEvent:方法寻找更合适的view。所以是,先传递事件,再根据事件在自己身上找更合适的view。
不管子控件是不是最合适的view,系统默认都要先把事件传递给子控件,经过子控件调用子控件自己的hitTest:withEvent:方法验证后才知道有没有更合适的view。即便父控件是最合适的view了,子控件的hitTest:withEvent:方法还是会调用,不然怎么知道有没有更合适的!即,如果确定最终父控件是最合适的view,那么该父控件的子控件的hitTest:withEvent:方法也是会被调用的。
八.网络通信原理
1.tcp的三次握手,4次挥手
TCP的状态 (SYN, FIN, ACK, PSH, RST, URG)
在TCP层,有个FLAGS字段,这个字段有以下几个标识:SYN, FIN, ACK, PSH, RST, URG.
其中,对于我们日常的分析有用的就是前面的五个字段。
它们的含义是:
SYN 表示建立连接,
FIN 表示关闭连接,
ACK 表示响应,
PSH 表示有 DATA数据传输,
RST 表示连接重置。
三次握手确认双方收发功能都正常,四次也可以但是显得比较多余
SYN : 发起一个新连接
seq : packet的数据部分的第一位应该在整个data stream中所在的位置 .(sequence number)
ACK : 确认序号有效. (acknowledge number)
FIN : 释放一个连接。
首先,源端口号和目标端口号是不可少的,如果没有这两个端口号,数据就不知道应该发给哪个应用。
接下来有包的序号,这个是为了解决包乱序的问题。
还有应该有的是确认号,目的是确认发出去对方是否有收到。如果没有收到就应该重新发送,直到送
达,这个是为了解决不丢包的问题。
接下来还有一些状态位。例如 SYN 是发起一个连接, ACK 是回复, RST 是重新连接, FIN 是
结束连接等。TCP 是面向连接的,因而双方要维护连接的状态,这些带状态位的包的发送,会引起双方
的状态变更。
还有一个重要的就是窗口大小。TCP 要做流量控制,通信双方各声明一个窗口(缓存大小),标识自己
当前能够的处理能力,别发送的太快,撑死我,也别发的太慢,饿死我。除了做流量控制以外,TCP还会做拥塞控制,对于真正的通路堵车不堵车,它无能为力,唯一能做的就
是控制自己,也即控制发送的速度。不能改变世界,就改变自己嘛。
TCP 头里有一个字段叫 Window ,也就是窗口大小。
这个字段是接收端告诉发送端自己还有多少缓冲区可以接收数据。于是发送端就可以根据这个接收端的
处理能力来发送数据,而不会导致接收端处理不过来。
所以,通常窗口的大小是由接收方的窗口大小来决定的。
2.三次握手实现的过程:
三次握手建立连接的首要目的是「同步序列号」。 只有同步了序列号才有可靠传输,TCP 许多特性都依赖于序列号实现,比如流量控制、丢包重传等,这 也是三次握手中的报文称为 SYN 的原因,SYN 的全称就 Synchronize Sequence Numbers(同步序 列号)
ACK: ACKnowledgment
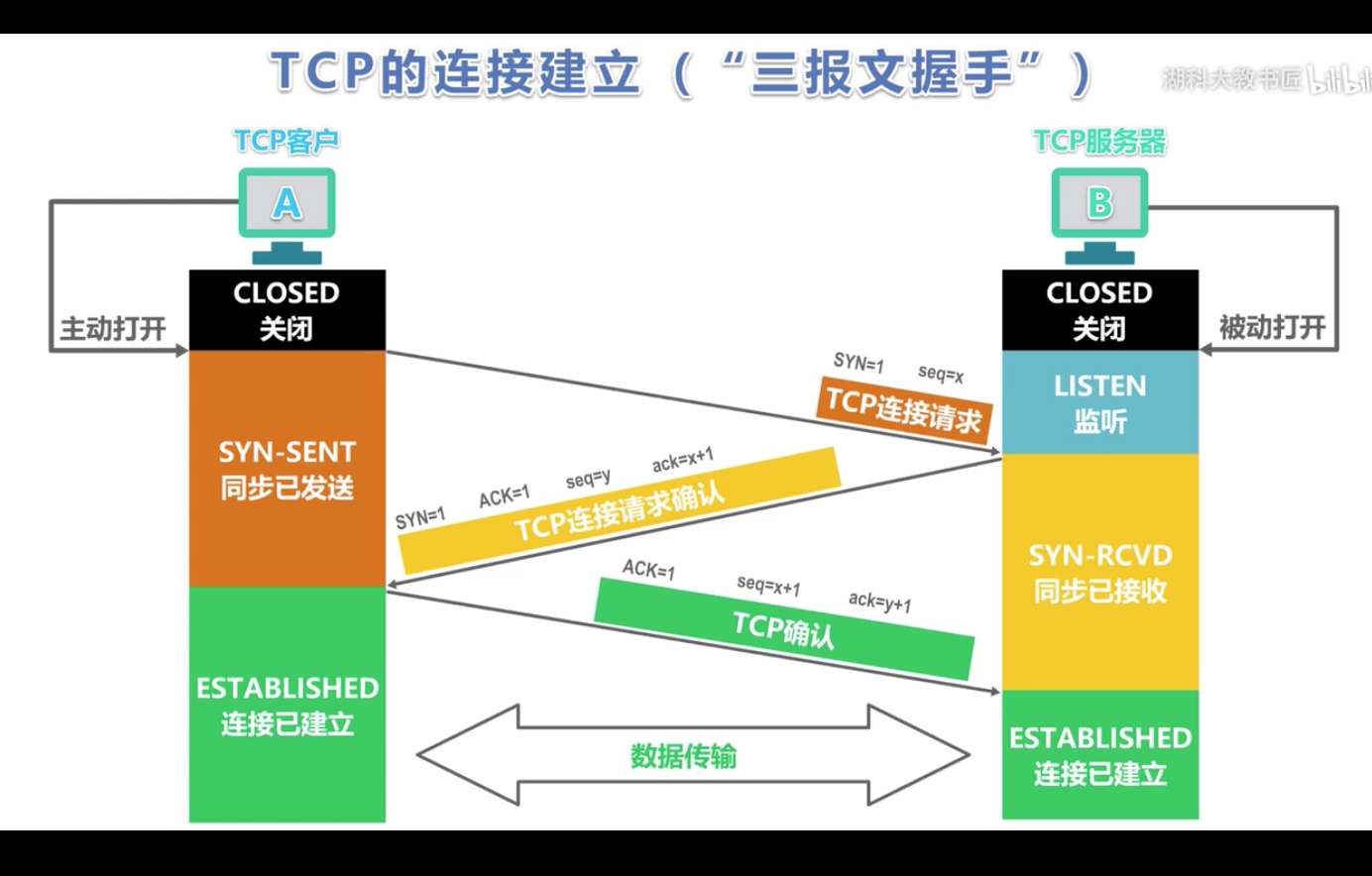
第一次握手:建立连接时,客户端发送同步序列编号到服务器,并进入发送状态,等待服务器确认 (SYN+seq)
第二次握手:服务器收到同步序列编号,确认并同时自己也发送一个同步序列编号+确认标志,此时服务器进入接收状态(SYN+ACK+seq)
第三次握手:客户端收到服务器发送的包,并向服务器发送确认标志,随后链接成功。(ACK+seq)
3.四次挥手:
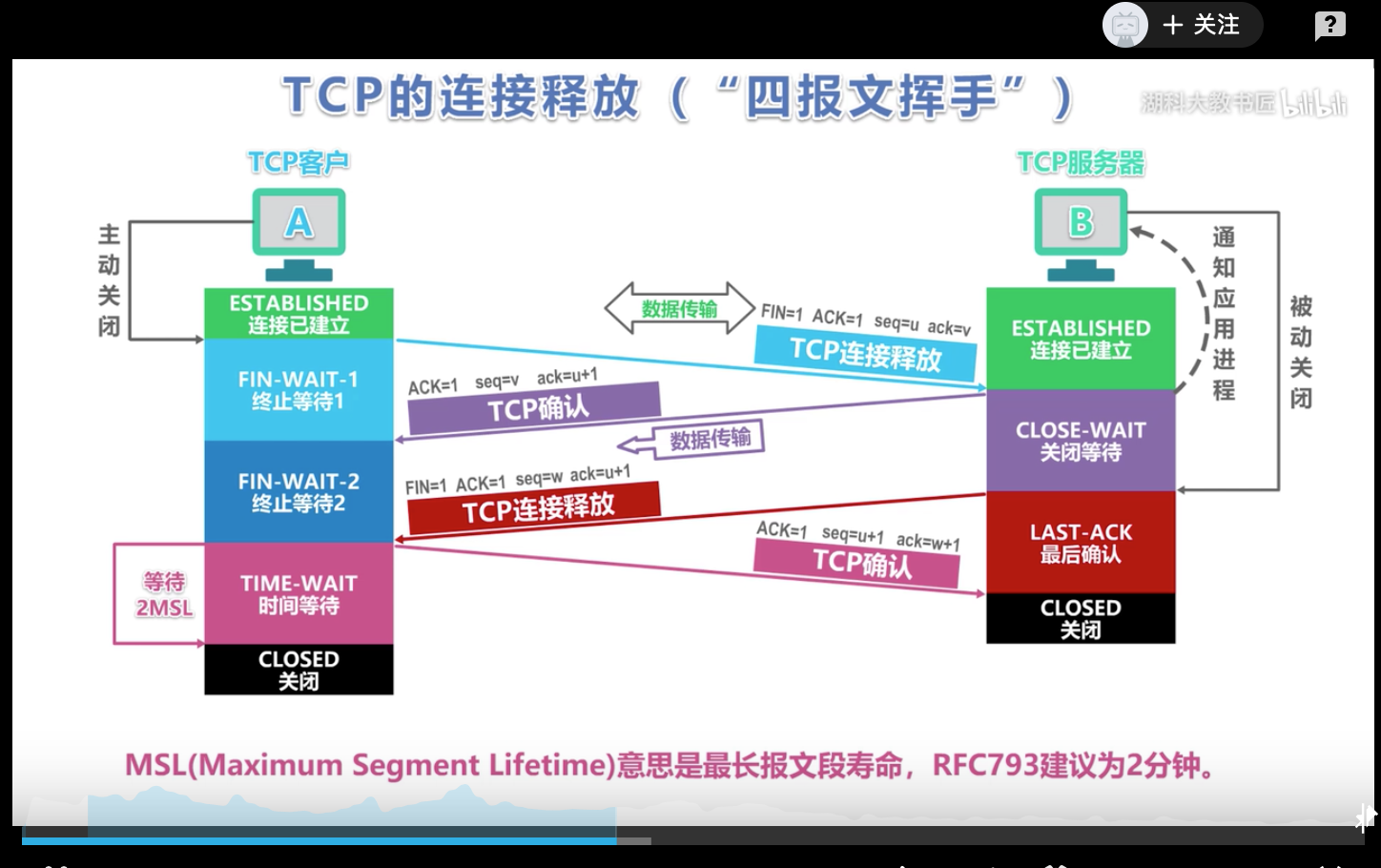
第一次:客户端向服务器发送一个带有结束标记的报文 (FIN + ACK + seq)
第二次:服务器收到报文后,向客户端发送一个确认序号,同时通知自己相应的应用程序,对方要求关闭连接 (ACK + seq)
第三次:服务器向客户端发送一个带有结束标记的报文 (FIN + ACK + seq)
第四次:客户端收到报文后,向服务器发送一个确认序号,链接关闭。(ACK + seq)
关于为什么3次握手4次挥手
握手
- 建立连接的双向确认: 在 TCP 握手过程中,客户端首先向服务器发送连接请求(SYN),服务器收到后回复确认消息(ACK)和自己的连接请求(SYN),客户端再次回复确认消息(ACK),这样双方都确认了对方的连接请求,建立了双向连接。
- 避免旧连接请求的影响: 如果只进行两次握手,那么可能会因为网络延迟或其他原因导致第一次握手的连接请求在网络中滞留,而第二次握手的连接请求却达到了服务器。此时服务器会误认为是一个新的连接请求,导致连接的混乱和不确定性。
- 防止过期连接的干扰: 如果只进行两次握手,那么可能会出现已经失效的连接请求在网络中重新被传递到服务器,导致服务器与客户端建立错误的连接。
挥手
- 双向连接: TCP 是一种全双工的通信协议,即客户端和服务器可以同时向对方发送和接收数据。因此,在关闭连接时,双方需要分别通知对方自己的关闭意图。
- 保证数据传输完整性: 在进行关闭连接之前,双方可能还有未传输完的数据,需要等待对方接收完毕或确认已经接收到数据,以确保数据传输的完整性。
- 保证数据可靠性: TCP 通过确认机制(ACK)来确保数据的可靠传输,需要进行多次确认来确认对方已经接收到数据。
基于以上原因,TCP 进行连接关闭时的过程是:
- 客户端发送关闭连接请求(FIN)给服务器,进入 FIN_WAIT_1 状态。
- 服务器收到关闭请求后,回复确认消息(ACK),进入 CLOSE_WAIT 状态。
- 服务器关闭发送数据的通道,发送关闭连接请求(FIN)给客户端,进入 LAST_ACK 状态。
- 客户端收到服务器的关闭请求后,回复确认消息(ACK),进入 TIME_WAIT 状态,等待一段时间(2MSL,两个最大报文段生存时间),确保服务器收到确认消息。
- 服务器收到客户端的确认消息后,进入 CLOSED 状态,连接关闭完成。
- 客户端在等待时间结束后,也进入 CLOSED 状态,连接关闭完成。
这样的挥手过程可以确保数据的完整性、可靠传输和正常关闭连接,防止数据丢失或混乱,保证通信的可靠性和稳定性
Charles抓包原理
Charles 是一款常用的网络调试工具,它可以用于网络抓包、查看请求和响应数据、模拟网络环境等功能。Charles 的劫持原理主要涉及以下几个方面:
- 中间人攻击: Charles 实际上通过中间人攻击的方式来实现网络请求和响应的劫持。它作为一个代理服务器,客户端和服务器之间的所有网络通信都经过 Charles,Charles 可以解析和修改这些通信数据。
- 证书生成: 为了使中间人攻击能够顺利进行,Charles 在启动时会生成自签名的根证书,并将这个证书安装到操作系统的信任列表中。这样,当客户端发起 HTTPS 请求时,Charles 可以使用自签名的证书来模拟服务器证书,使得客户端可以建立连接并信任 Charles 的证书。
- 数据截获与修改: 当客户端发送请求或服务器返回响应时,数据会经过 Charles 的代理服务器。Charles 可以截获这些数据并显示在界面上,用户可以查看请求和响应的详细信息,包括请求头、请求体、响应头、响应体等。此外,Charles 还可以对这些数据进行修改,比如修改请求参数、修改响应内容等。
- SSL/TLS 解密: 对于 HTTPS 请求,Charles 可以通过自身的证书来解密 SSL/TLS 加密的数据,这样即使是加密的通信内容,也可以在 Charles 中查看明文数据,便于调试和分析。
总体来说,Charles 的劫持原理是利用自身作为代理服务器,截获客户端和服务器之间的网络通信数据,并提供查看和修改这些数据的功能,以实现网络请求和响应的劫持、调试和分析。需要注意的是,在实际使用中应谨慎处理敏感数据,避免泄露隐私信息。
4.Socket
socket是对TCP/IP协议的封装,Socket本身并不是协议,而是一个调用接口(API),通过Socket,我们才能使用TCP/IP协议。实际上,Socket跟TCP/IP协议没有必然的联系。Socket编程接口在设计的时候,就希望也能适应其他的网络协议。所以说,Socket的出现只是使得程序员更方便地使用TCP/IP协议栈而已,是对TCP/IP协议的抽象,从而形成了我们知道的一些最基本的函数接口,比如create、listen、connect、accept、send、read和write等等。网络有一段关于socket和TCP/IP协议关系的说法比较容易理解:
“TCP/IP只是一个协议栈,就像操作系统的运行机制一样,必须要具体实现,同时还要提供对外的操作接口。这个就像操作系统会提供标准的编程接口,比如win32编程接口一样,TCP/IP也要提供可供程序员做网络开发所用的接口,这就是Socket编程接口。”
socket是纯C语言的,跨平台
应用层:TFTP,HTTP,SNMP,FTP,SMTP,DNS,Telnet 等等
传输层:TCP,UDP
网络层:IP,ICMP,OSPF,EIGRP,IGMP
数据链路层:SLIP,CSLIP,PPP,MTU
5.单双工
单工: 单工通信只支持信号在一个方向上传输(正向或反向),任何时候不能改变信号的传输方向。
(读卡器,打印机)
半双工: 半双工通信允许信号在两个方向上传输,但某一时刻只允许信号在一个信道上单向传输。
(BB机)
全双工: 全双工通信允许数据同时在两个方向上传输,即有两个信道,因此允许同时进行双向传输。
(电话机)
6.http和websocket的长连接区别
HTTP1.1通过使用Connection:keep-alive进行长连接,HTTP 1.1默认进行持久连接。在一次 TCP 连接中可以完成多个 HTTP 请求,但是对每个请求仍然要单独发 header,Keep-Alive不会永久保持连接,它有一个保持时间,可以在不同的服务器软件(如Apache)中设定这个时间。这种长连接是一种“伪链接”
websocket的长连接,是一个真的全双工。长连接第一次tcp链路建立之后,后续数据可以双方都进行发送,不需要发送请求头。
keep-alive双方并没有建立正真的连接会话,服务端可以在任何一次请求完成后关闭。WebSocket 它本身就规定了是正真的、双工的长连接,两边都必须要维持住连接的状态。
7.HTTPS
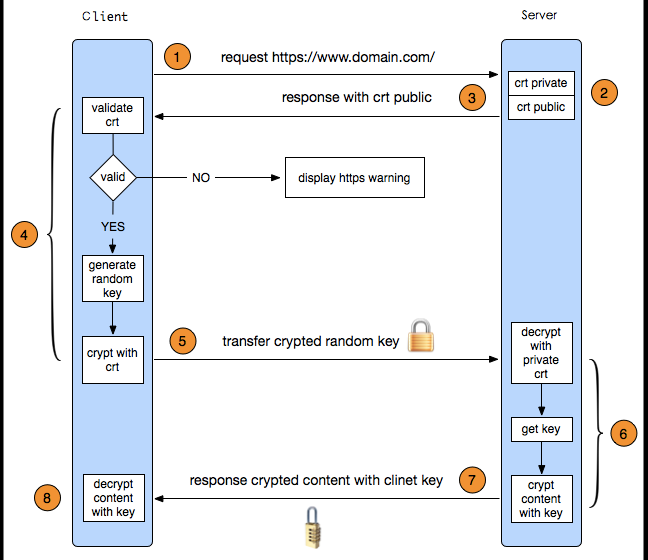
- 客户端发起 HTTPS 请求:
- 客户端(例如浏览器)向服务器发起 HTTPS 请求,请求的 URL 以 “https://“ 开头,表示使用 HTTPS 协议进行通信。
- 服务器准备 SSL/TLS 证书:
- 服务器需要准备一份有效的 SSL/TLS 数字证书,用于验证服务器身份和加密通信数据。
- 数字证书通常由权威的证书颁发机构(CA,Certificate Authority)签发,用于证明服务器的身份和公钥。
- 建立安全连接:
- 客户端向服务器发起握手请求,请求建立安全连接。
- 服务器返回 SSL/TLS 证书给客户端。
- 客户端验证服务器的证书是否有效和可信(验证证书的颁发者、有效期、域名匹配等),如果验证通过,则生成对称加密密钥(Session Key)。
- 加密通信:
- 客户端使用服务器返回的公钥对对称密钥进行加密,并发送给服务器。
- 服务器使用私钥解密客户端发送的对称密钥,得到对称密钥。
- 客户端和服务器之间的通信数据使用对称密钥进行加密和解密,保证通信的安全性。
- 数据传输:
- 客户端和服务器之间使用建立的安全连接进行数据传输,数据在传输过程中被加密保护,第三方无法窃听和篡改通信内容。
- 维护安全连接:
- 客户端和服务器之间的安全连接通常会保持一段时间(Session),可以通过会话缓存或者 HTTPS Keep-Alive 来提高连接效率和减少握手开销。
关于客户端公钥的验证(SSL/TLS 证书)
- 获取服务器证书: iOS 客户端在建立 HTTPS 连接时,会从服务器端获取证书。证书包含了服务器的公钥以及其他信息,如证书颁发者、有效期等。
- 验证证书链: iOS 客户端会首先验证服务器证书的有效性,包括:
- 是否由信任的证书颁发机构颁发(如根证书或中间证书颁发机构)。
- 证书的有效期是否在当前时间范围内。
- 证书的域名是否与服务器域名匹配(域名验证)。
- 获取服务器公钥: 验证证书链通过后,iOS 客户端会从服务器证书中提取服务器的公钥。
- 验证公钥有效性: iOS 客户端会使用系统内置的信任链(Trust Store)来验证服务器公钥的有效性。这些信任链包含了信任的根证书和中间证书颁发机构的证书。
- 验证证书是否被吊销: iOS 客户端还会检查服务器证书是否被吊销,通常会通过在线的证书吊销列表(Certificate Revocation List,CRL)或在线证书状态协议(Online Certificate Status Protocol,OCSP)来检查证书的状态。
- 建立安全连接: 如果服务器公钥验证通过,iOS 客户端会使用服务器的公钥来建立安全连接,并开始加密通信。
8.DNS
那么实现这一技术的就是 DNS 域名解析,DNS 可以将域名网址自动转换为具体的 IP 地址。
域名的层级关系
DNS 中的域名都是用句点来分隔的,比如 www.server.com ,这里的句点代表了不同层次之间的界限。
在域名中,越靠右的位置表示其层级越高。
所以域名的层级关系类似一个树状结构:
根 DNS 服务器
顶级域 DNS 服务器(com)
权威 DNS 服务器(server.com)
9.NAT
Version:0.9 StartHTML:0000000105 EndHTML:0000002360 StartFragment:0000000141 EndFragment:0000002320
此时,两个私有 IP 地址都转换 IP 地址为公有地址 120.229.175.121,但是以不同的端口号作为区分。
于是,生成一个 NAPT 路由器的转换表,就可以正确地转换地址跟端口的组合,令客户端 A、B 能同时
与服务器之间进行通信。
10.ICMP
ICMP 全称是 Internet Control Message Protocol,也就是互联网控制报文协议。
11.响应者链
- 正因为hitTest:withEvent:方法可以返回最合适的view,所以可以通过重写hitTest:withEvent:方法,返回指定的view作为最合适的view。
- 不管点击哪里,最合适的view都是hitTest:withEvent:方法中返回的那个view。
- 通过重写hitTest:withEvent:,就可以拦截事件的传递过程,想让谁处理事件谁就处理事件。
事件传递给谁,就会调用谁的hitTest:withEvent:方法。
注 意:如果hitTest:withEvent:方法中返回nil,那么调用该方法的控件本身和其子控件都不是最合适的view,也就是在自己身上没有找到更合适的view。那么最合适的view就是该控件的父控件。
所以事件的传递顺序是这样的:
产生触摸事件->UIApplication事件队列->[UIWindow hitTest:withEvent:]->返回更合适的view->[子控件 hitTest:withEvent:]->返回最合适的view事件传递给窗口或控件的后,就调用hitTest:withEvent:方法寻找更合适的view。所以是,先传递事件,再根据事件在自己身上找更合适的view。
不管子控件是不是最合适的view,系统默认都要先把事件传递给子控件,经过子控件调用子控件自己的hitTest:withEvent:方法验证后才知道有没有更合适的view。即便父控件是最合适的view了,子控件的hitTest:withEvent:方法还是会调用,不然怎么知道有没有更合适的!即,如果确定最终父控件是最合适的view,那么该父控件的子控件的hitTest:withEvent:方法也是会被调用的。
技巧:想让谁成为最合适的view就重写谁自己的父控件的hitTest:withEvent:方法返回指定的子控件,或者重写自己的hitTest:withEvent:方法 return self。但是,建议在父控件的hitTest:withEvent:中返回子控件作为最合适的view!
12.客户端发起网络请求的完整过程
1 | 1.DNS解析:客户端首先需要将请求的域名解析成对应的IP地址,以便能够建立与服务器的连接。 |
13.计算机网络分层
网络分层是指将计算机网络功能分解为不同的层次,每个层次负责特定的任务和功能,以实现网络通信的可靠性、灵活性和可维护性。常见的网络分层模型包括 OSI 模型(Open Systems Interconnection,开放系统互联模型)和 TCP/IP 模型(Transmission Control Protocol/Internet Protocol,传输控制协议/互联网协议)。
- OSI 模型: OSI 模型将网络通信划分为七个层次,从底层到顶层依次是物理层、数据链路层、网络层、传输层、会话层、表示层和应用层。每个层次都有特定的功能和责任:
- 物理层:负责传输原始比特流,定义物理介质和电信号规范。
- 数据链路层:处理相邻节点之间的数据传输,提供帧的组装和解析、物理地址的寻址和流量控制等功能。
- 网络层:负责数据包的路由和转发,实现不同网络之间的通信和数据包的传输。
- 传输层:提供端到端的可靠数据传输,包括数据分段、流量控制、拥塞控制等。
- 会话层:管理和协调会话(Session)的建立、维护和结束,确保数据的可靠传输。
- 表示层:负责数据的格式转换、加密解密、压缩解压缩等,确保不同系统之间的数据交换兼容性。
- 应用层:提供用户接口和网络服务,包括文件传输、电子邮件、远程登录等。
- TCP/IP 模型: TCP/IP 模型将网络通信划分为四个层次,从底层到顶层依次是网络接口层(网络接入层)、网络层、传输层和应用层。它与 OSI 模型有一定的对应关系,但更加简化和实用:
- 网络接口层:负责将数据包封装成帧并发送到物理介质上,与 OSI 模型的物理层和数据链路层类似。
- 网络层:处理数据包的路由和转发,与 OSI 模型的网络层功能相似。
- 传输层:提供端到端的可靠数据传输,与 OSI 模型的传输层功能相似,主要包括 TCP 和 UDP 协议。
- 应用层:提供各种网络应用和服务,与 OSI 模型的应用层功能类似,包括 HTTP、FTP、SMTP 等协议。
关于Socket
Socket 不是一个独立的网络协议或网络层,它是一种编程接口或抽象概念,用于实现在网络上进行通信的应用程序。在计算机网络中,Socket 通常与传输层(第四层)相关联,因为它提供了应用程序与网络传输协议(如 TCP、UDP)之间的接口。
具体来说,Socket 是一种编程接口,由操作系统提供,用于在网络上进行数据传输。它将传输层协议(如 TCP 或 UDP)提供的通信能力封装成一种 API,使得应用程序可以方便地使用网络进行数据交换。在实际编程中,Socket 主要用于在应用层实现网络通信,但它本身并不属于 OSI 模型或 TCP/IP 模型中的任何一个具体的网络层次。
总之,Socket 是一种编程接口或抽象概念,用于在网络上进行通信的应用程序接口,它通常与传输层(第四层)相关联,但本身不属于 OSI 模型或 TCP/IP 模型中的某一具体网络层次。
关于MTU
MTU 是网络通信中的一个重要概念,表示最大传输单元(Maximum Transmission Unit)。它指的是网络中能够通过的最大数据包的大小,以字节为单位。如果数据包的大小超过了 MTU,那么就需要进行分片(Fragmentation)处理,将数据包分成更小的片段进行传输,然后在接收端重新组装。
MTU 的大小通常由网络设备(如路由器、交换机)或网络协议(如以太网、PPP)决定,不同的网络类型和设备可能会有不同的 MTU 设置。常见的以太网 MTU 大小是 1500 字节,在一些特定网络环境下也可以设置为其他值,如 Jumbo Frames 中的 9000 字节。
了解 MTU 的概念对于网络通信非常重要,特别是在处理大量数据或进行网络优化时。在开发网络应用程序时,有时需要考虑 MTU 大小,以避免数据包过大导致分片、重传等问题,从而影响网络性能。
九.iOS本地持久化
NSUserDefaults
plist
Keychain(钥匙串)
归档
沙盒写入数据库
1.NSUserDefaults
用于存储用户的偏好设置和用户信息,如用户名,是否自动登录,字体大小等.
数据自动保存在沙盒的Libarary/Preferences目录下.
NSUserDefaults将输入的数据储存在.plist格式的文件下,这种存储方式就决定了它的安全性几乎为0,所以不建议存储一些敏感信息如:用户密码,token,加密私钥等!
它能存储的数据类型为:NSNumber(NSInteger、float、double),NSString,NSDate,NSArray,NSDictionary,BOOL. 不支持自定义对象的存储.
2.plist
即属性列表文件,全名是Property List,这种文件的扩展名为.plist,因此,通常被叫做plist文件。它是一种用来存储串行化后的对象的文件,用于存储程序中经常用到且数据量小而不经常改动的数据。
可以存储的类型:NSNumber,NSString,NSDate,NSData ,NSArray,NSDictionary,BOOL.
不支持自定义对象的存储.
3.Keychain
用于本地重要数据的存储,将数据加密后存储在本地更安全.如:密码,秘钥,序列号等.当你删除APP后Keychain存储的数据不会删除,所以在重装App后,Keychain里的数据还能使用。从ios 3.0开始,跨程序分享keychain变得可行而NSUserDefaults存储的数据会随着APP而删掉.
使用keychain时苹果官方已经为我们封装好了文件KeychainItemWrapper,引入即可使用.当然也可是使用其他优秀的第三方的封装,比如ssKeychain,使用方法如下:
使用方法
在 iOS 中,Keychain 是一种安全的数据存储机制,用于存储敏感信息,例如密码、证书、令牌等。Keychain 中的数据是加密存储的,并且受到系统级的保护,因此相比于普通的数据存储方式,Keychain 提供了更高的安全性。
Keychain 中的数据实际上存储在设备的闪存中,这是一个加密的数据库,只有经过授权的应用才能够访问其中的数据。Keychain 数据不会随着应用的删除而被删除,这是因为 Keychain 是系统级的存储机制,属于设备级别的存储,不同于应用级别的存储。
当你删除应用后,Keychain 中的数据仍然会保留,这样设计的目的是为了确保用户在重新安装应用时可以恢复之前存储的敏感信息,例如用户的登录凭据、令牌等。这也是为了提高用户体验和数据的持久性,避免用户在重新安装应用时需要重新登录或者重新配置敏感信息。
需要注意的是,虽然 Keychain 中的数据在应用删除后仍然保留,但只有安装了相同签名的应用才能够访问之前存储的 Keychain 数据。换句话说,不同应用之间无法共享 Keychain 数据,确保了数据的安全性和隔离性。
4.归档(NSKeyedArchiver)
归档是iOS开发中数据存储常用的技巧,归档可以直接将对象储存成文件,把文件读取成对象。
相对于plist或者userdefault形式,归档可以存储的数据类型更加多样,并且可以存取自定义对象。对象归档的文件是保密的,在磁盘上无法查看文件中的内容,更加安全。
遵守NSCoding协议,并实现该协议中的两个方法。如果是继承,则子类一定要重写那两个方法。因为子类在存取的时候,会去子类中去找调用的方法,没找到那么它就去父类中找,所以最后保存和读取的时候新增加的属性会被忽略。需要先调用父类的方法,先初始化父类的,再初始化子类的。
保存数据的文件的后缀名可以随意命名。
demo
5.沙盒写入
持久化在Document目录下,一般存储非机密数据。当App中涉及到电子书阅读、听音乐、看视频、刷图片列表等时,推荐使用沙盒存储。因为这可以极大的节约用户流量,而且也增强了app的体验效果.
Application:存放程序源文件,上架前经过数字签名,上架后不可修改。
Documents: 保存应⽤运行时生成的需要持久化的数据,iTunes同步设备时会备份该目录。例如,游戏应用可将游戏存档保存在该目录。
tmp: 保存应⽤运行时所需的临时数据,使⽤完毕后再将相应的文件从该目录删除。应用 没有运行时,系统也可能会清除该目录下的文件。iTunes同步设备时不会备份该目录。
Library/Caches: 保存应用运行时⽣成的需要持久化的数据,iTunes同步设备时不会备份 该目录。⼀一般存储体积大、不需要备份的非重要数据,比如网络数据缓存存储到Caches下
Library/Preference: 保存应用的所有偏好设置,如iOS的Settings(设置) 应⽤会在该目录中查找应⽤的设置信息。iTunes同步设备时会备份该目录。
6.数据库
适合储存数据量较大的数据,一般使用FMDB和CoreData来实现.
FMDB:
FMDB是iOS平台的SQLite数据库框架,FMDB以OC的方式封装了SQLite的C语言API,使用起来更加面向对象,省去了很多麻烦、冗余的C语言代码,对比苹果自带的Core Data框架,更加轻量级和灵活,提供了多线程安全的数据库操作方法,有效地防止数据混乱。CoreData:
Core Data是iOS5之后才出现的一个框架,它提供了对象-关系映射(ORM)的功能,即能够将OC对象转化成数据,保存在SQLite数据库文件中,也能够将保存在数据库中的数据还原成OC对象。在此数据操作期间,我们不需要编写任何SQL语句.但是直接操作CoreData显的不是那么容易,所以我多数的时候会使用MagicRecord来实现.MagicRecord是对CoreData的二次封装,使用起来简单操作方便.
十.hybrid app 开发原理 , flutter原理
ReactNative 和 weex 对比
JS引擎:
weex使用V8, ReactNative使用JSCore
JS开发框架:
weex基于vue.js(2W+ star)。小巧轻量的前端开发框架,组件化,数据绑定,2.0引入virtual dom。
ReactNative使用React(4W+ star)。革命性的前端开发框架,组件化,数据绑定,virtual dom。
Weex和React Native不同的是,Weex把JS Framework内置在SDK里面,用来解析从服务器上下载的JS Bundle,这样也减少了每个JS Bundle的体积,不再有React Native需要分包的问题。
flutter
前言: 比如使用 WebView 跨平台方式,优点确实非常明显。基于 WebView 的框架集成了当下 Web 开发的诸多优势:丰富的控件库、动态化、良好的技术社区、测试自动化等等。但是缺点也同样明显:渲染效率和 JavaScript 的执行能力都比较差,使页面的加载速度和用户体验都不尽如人意。
而使用以 React Native(简称 RN)为代表的框架时,维护又成了大难题。RN 使用类 HTML+JS 的 UI 创建逻辑,生成对应的原生页面,将页面的渲染工作交给了系统,所以渲染效率有很大的优势。但由于 RN 代码是通过 JS 桥接的方式转换为原生的控件,所以受各个系统间的差异影响非常大,虽然可以开发一套代码,但对各个平台的适配却非常的繁琐和麻烦。
Flutter 架构和实现原理
Flutter 使用 Dart 语言开发,主要有以下几点原因:
- Dart 一般情况下是运行 DartVM 上,但是也可以编译为 ARM 代码直接运行在硬件上。
- Dart 同时支持 AOT 和 JIT 两种编译方式,可以更好的提高开发以及 App 的执行效率。
- Dart 可以利用独特的隔离区(Isolate)实现多线程。而且不共享内存,可以实现无锁快速分配。
- 分代垃圾回收,非常适合 UI 框架中常见的大量 Widgets 对象创建和销毁的优化。
- 在为创建的对象分配内存时,Dart 是在现有的堆上移动指针,保证内存的增长是程线性的,于是就省了查找可用内存的过程。
Dart 主要由 Google 负责开发和维护。目前 Dart 最新版本已经是 2.2,针对 App 和 Web 开发做了很多优化。并且对于大多数的开发者而言,Dart 的学习成本非常低。
Flutter 架构也是采用的分层设计。从下到上依次为:Embedder(嵌入器)、Engine、Framework。
混编教程:https://github.com/flutter/flutter/wiki/Add-Flutter-to-existing-apps
展望 :
- 虽然 1.2 版本已经发布,但是目前没有达到完全稳定状态,1.2 发布完了就出现了控件渲染的问题。加上 Dart 语言生态小,学习资料可能不够丰富。
- 关于动态化的支持,目前 Flutter 还不支持线上动态性。如果要在 Android 上实现动态性相对容易些,iOS 由于审核原因要实现动态性可能成本很高。
- Flutter 中目前拿来就用的能力只有 UI 控件和 Dart 本身提供能力,对于平台级别的能力还需要通过 channel 的方式来扩展。
- 已有工程迁移比较复杂,以前沉淀的 UI 控件,需要重新再实现一套。
- 最后一点比较有争议,Flutter 不会从程序中拆分出额外的模板或布局语言,如 JSX 或 XM L,也不需要单独的可视布局工具。有的人认为配合 HotReload 功能使用非常方便,但我们发现这样代码会有非常多的嵌套,阅读起来有些吃力。
十一.性能优化
1.卡顿检测以及原理
runloop卡顿检测 : 平时所说的“卡顿”主要是因为在主线程执行了比较耗时的操作
除了用xcode的Time profiler (程序耗时检测), Core Animation(检测刷新帧率)工具外,代码层面也可以检测.
可以添加Observer到主线程RunLoop中,通过监听RunLoop状态切换的耗时,以达到监控卡顿的目的
检测runloop间隔,打印主线程堆栈消息转发解决定时器循环引用 :
GCD定时器封装:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
> dispatch_queue_t queue = dispatch_get_main_queue();
> //只要不是主队列,gcd定时器就在子线程执行任务
> // dispatch_queue_t queue = dispatch_queue_create("timer", DISPATCH_QUEUE_SERIAL);
>
> //创建定时器
> dispatch_source_t timer = dispatch_source_create(DISPATCH_SOURCE_TYPE_TIMER, 0, 0, queue);
>
> // 设置时间
> uint64_t start = 2.0;
> uint64_t interval = 1.0;
> dispatch_source_set_timer(timer,
> dispatch_time(DISPATCH_TIME_NOW, start * NSEC_PER_SEC),
> interval * NSEC_PER_SEC, 0);
>
> // 设置回调
> dispatch_source_set_event_handler(timer, ^{
>
> });
> // 启动定时器
> dispatch_resume(timer);
>
>
NSProxy消息转发 : NSProxy是苹果用来消息转发的类,消息转发效率更高.
Tagged Pointerv : 从64bit开始,iOS引入了Tagged Pointer技术,用于优化NSNumber、NSDate、NSString等小对象的存储 . 在没有使用Tagged Pointer之前, NSNumber等对象需要动态分配内存、维护引用计数等,NSNumber指针存储的是堆中NSNumber对象的地址值
二: 性能优化,卡顿产生原理以及优化
2.1 CPU和GPU卡顿原因
CPU和GPU
在屏幕成像的过程中,CPU和GPU起着至关重要的作用
CPU(Central Processing Unit,中央处理器)
对象的创建和销毁、对象属性的调整、布局计算、文本的计算和排版、图片的格式转换和解码、图像的绘制(Core Graphics)GPU(Graphics Processing Unit,图形处理器)
纹理的渲染在iOS中是双缓冲机制,有前帧缓存、后帧缓存 .每次垂直同步信号出来时候,把处理好的帧显示在屏幕上.按照60FPS的刷帧率,每隔16ms就会有一次VSync信号.垂直同步信号来的时候,GPU如果没有处理完成,只能将上一次处理好的帧显示出来,这就是掉帧,等下一次垂直同步信号出来后,这个数据处理好后再显示.
卡顿解决的主要思路
尽可能减少CPU、GPU资源消耗2.2 卡顿解决方案
- 卡顿优化 - CPU
1 尽量用轻量级的对象,比如用不到事件处理的地方,可以考虑使用CALayer取代UIView(下划线)
2 不要频繁地调用UIView的相关属性,比如frame、bounds、transform等属性,尽量减少不必要的修改
3 尽量提前计算好布局,在有需要时一次性调整对应的属性,不要多次修改属性
4 Autolayout会比直接设置frame消耗更多的CPU资源
5 图片的size最好刚好跟UIImageView的size保持一致
6 控制一下线程的最大并发数量
7 尽量避免日期格式转换 [NSDate dateWithString:@”1990-11-11” format:@”yyyy-MM-dd”]
8 尽量把耗时的操作放到子线程
文本处理(尺寸计算、绘制)
图片处理(解码、绘制)9 tableView不要动态创建子控件,尽可能使用懒加载,尽量少设置透明度.
- 卡顿优化 - GPU
尽量避免短时间内大量图片的显示,尽可能将多张图片合成一张进行显示
GPU能处理的最大纹理尺寸是4096x4096,一旦超过这个尺寸,就会占用CPU资源进行处理,所以纹理尽量不要超过这个尺寸
尽量减少视图数量和层次
减少透明的视图(alpha<1),不透明的就设置opaque为YES
尽量避免出现离屏渲染
在OpenGL中,GPU有2种渲染方式
On-Screen Rendering:当前屏幕渲染,在当前用于显示的屏幕缓冲区进行渲染操作
Off-Screen Rendering:离屏渲染,在当前屏幕缓冲区以外新开辟一个缓冲区进行渲染操作离屏渲染消耗性能的原因
需要创建新的缓冲区
离屏渲染的整个过程,需要多次切换上下文环境,先是从当前屏幕(On-Screen)切换到离屏(Off-Screen);等到离屏渲染结束以后,将离屏缓冲区的渲染结果显示到屏幕上,又需要将上下文环境从离屏切换到当前屏幕
- 离屏渲染
哪些操作会触发离屏渲染?
光栅化,layer.shouldRasterize = YES遮罩,layer.mask
圆角,同时设置layer.masksToBounds = YES、layer.cornerRadius大于0
考虑通过CoreGraphics绘制裁剪圆角,或者叫UI提供圆角图片用 Instuments 的 GPU Driver 预设,能够实时查看到 CPU 和 GPU 的资源消耗。在这个预设内,你能查看到几乎所有与显示有关的数据,比如 Texture 数量、CA 提交的频率、GPU 消耗等,在定位界面卡顿的问题时。
- 图片加载
1.加载小图片\使用频率比较高的图片
1> 利用imageNamed:方法加载过的图片, 永远有缓存, 这个缓存是由系统管理的, 无法通过代码销毁缓存
通过 imageNamed 创建 UIImage 时,系统实际上只是在 Bundle 内查找到文件名,然后把这个文件名放到 UIImage 里返回,并没有进行实际的文件读取和解码。当 UIImage 第一次显示到屏幕上时,其内部的解码方法才会被调用,同时解码结果会保存到一个全局缓存去。在图片解码后,App 第一次退到后台和收到内存警告时,该图片的缓存才会被清空,其他情况下缓存会一直存在。
2.加载大图片\使用频率比较低的图片(一次性的图片, 比如版本新特性的图片)
1> 利用initWithContentsOfFile:\imageWithContentsOfFile:等方法加载过的图片, 没有缓存, 只要用完了, 就会自动销毁2.3 耗电网络优化
CPU处理,Processing
网络,Networking
定位,Location
图像,Graphics
- 耗电优化
尽可能降低CPU、GPU功耗,少用定时器
PerformSelecter
当调用 NSObject 的 performSelecter:afterDelay: 后,实际上其内部会创建一个 Timer 并添加到当前线程的 RunLoop 中。所以如果当前线程没有 RunLoop,则这个方法会失效。当调用 performSelector:onThread: 时,实际上其会创建一个 Timer 加到对应的线程去,同样的,如果对应线程没有 RunLoop 该方法也会失效。
- 优化I/O操作
尽量不要频繁写入小数据,最好批量一次性写入
读写大量重要数据时,考虑用dispatch_io,其提供了基于GCD的异步操作文件I/O的API。用dispatch_io系统会优化磁盘访问
数据量比较大的,建议使用数据库(比如SQLite、CoreData)- 网络优化
减少、压缩网络数据
如果多次请求的结果是相同的,尽量使用缓存
使用断点续传,否则网络不稳定时可能多次传输相同的内容
网络不可用时,不要尝试执行网络请求
让用户可以取消长时间运行或者速度很慢的网络操作,设置合适的超时时间
批量传输,比如,下载视频流时,不要传输很小的数据包,直接下载整个文件或者一大块一大块地下载。如果下载广告,一次性多下载一些,然后再慢慢展示。如果下载电子邮件,一次下载多封,不要一封一封地下载- 定位优化
如果只是需要快速确定用户位置,最好用CLLocationManager的requestLocation方法。定位完成后,会自动让定位硬件断电
如果不是导航应用,尽量不要实时更新位置,定位完毕就关掉定位服务
尽量降低定位精度,比如尽量不要使用精度最高的kCLLocationAccuracyBest
需要后台定位时,尽量设置pausesLocationUpdatesAutomatically为YES,如果用户不太可能移动的时候系统会自动暂停位置更新
尽量不要使用startMonitoringSignificantLocationChanges,优先考虑startMonitoringForRegion:- 硬件检测优化
用户移动、摇晃、倾斜设备时,会产生动作(motion)事件,这些事件由加速度计、陀螺仪、磁力计等硬件检测。在不需要检测的场合,应该及时关闭这些硬件
三: app启动速度优化
3.1 启动流程
APP的启动可以分为2种
冷启动(Cold Launch):从零开始启动APP
热启动(Warm Launch):APP已经在内存中,在后台存活着,再次点击图标启动APPAPP启动时间的优化,主要是针对冷启动进行优化
通过添加环境变量可以打印出APP的启动时间分析(Edit scheme -> Run -> Arguments)
DYLD_PRINT_STATISTICS设置为1
如果需要更详细的信息,那就将DYLD_PRINT_STATISTICS_DETAILS设置为1
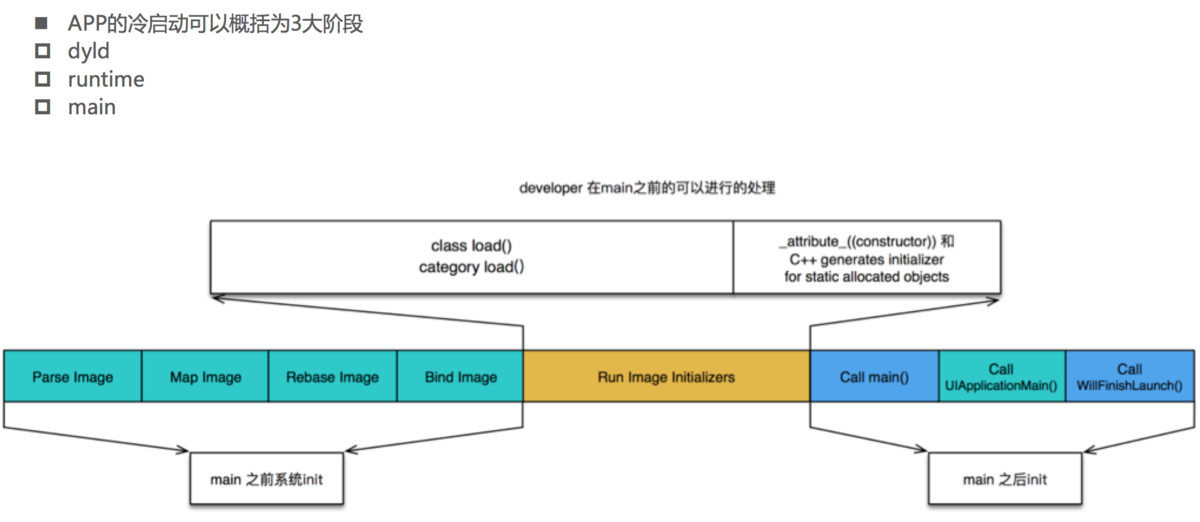
dyld(dynamic link editor),Apple的动态链接器,可以用来装载Mach-O文件(可执行文件、动态库等)
启动APP时,dyld所做的事情有
装载APP的可执行文件(可执行文件包含代码和动态库依赖信息),同时会递归加载所有依赖的动态库
可执行文件
当dyld把可执行文件、动态库都装载完毕后,会通知Runtime进行下一步的处理
启动APP时,runtime所做的事情有
调用map_images进行可执行文件内容的解析和处理
在load_images中调用call_load_methods,调用所有Class和Category的+load方法
进行各种objc结构的初始化(注册Objc类 、初始化类对象等等)
调用C++静态初始化器和attribute((constructor))修饰的函数到此为止,可执行文件和动态库中所有的符号(Class,Protocol,Selector,IMP,…)都已经按格式成功加载到内存中,被runtime 所管理
总结一下
APP的启动由dyld主导,将可执行文件加载到内存,顺便加载所有依赖的动态库
并由runtime负责加载成objc定义的结构
所有初始化工作结束后,dyld就会调用main函数
接下来就是UIApplicationMain函数,AppDelegate的application:didFinishLaunchingWithOptions:方法3.2 启动优化
按照不同的阶段
dyld
减少动态库、合并一些动态库(定期清理不必要的动态库)
减少Objc类、分类的数量、减少Selector数量(定期清理不必要的类、分类), 装在可执行文件时候有加载类分类的操作.
减少C++虚函数数量runtime
少在+load方法里写逻辑代码可以用+initialize方法和dispatch_once取代main
在不影响用户体验的前提下,尽可能将一些操作延迟,不要全部都放在finishLaunching方法中
按需加载
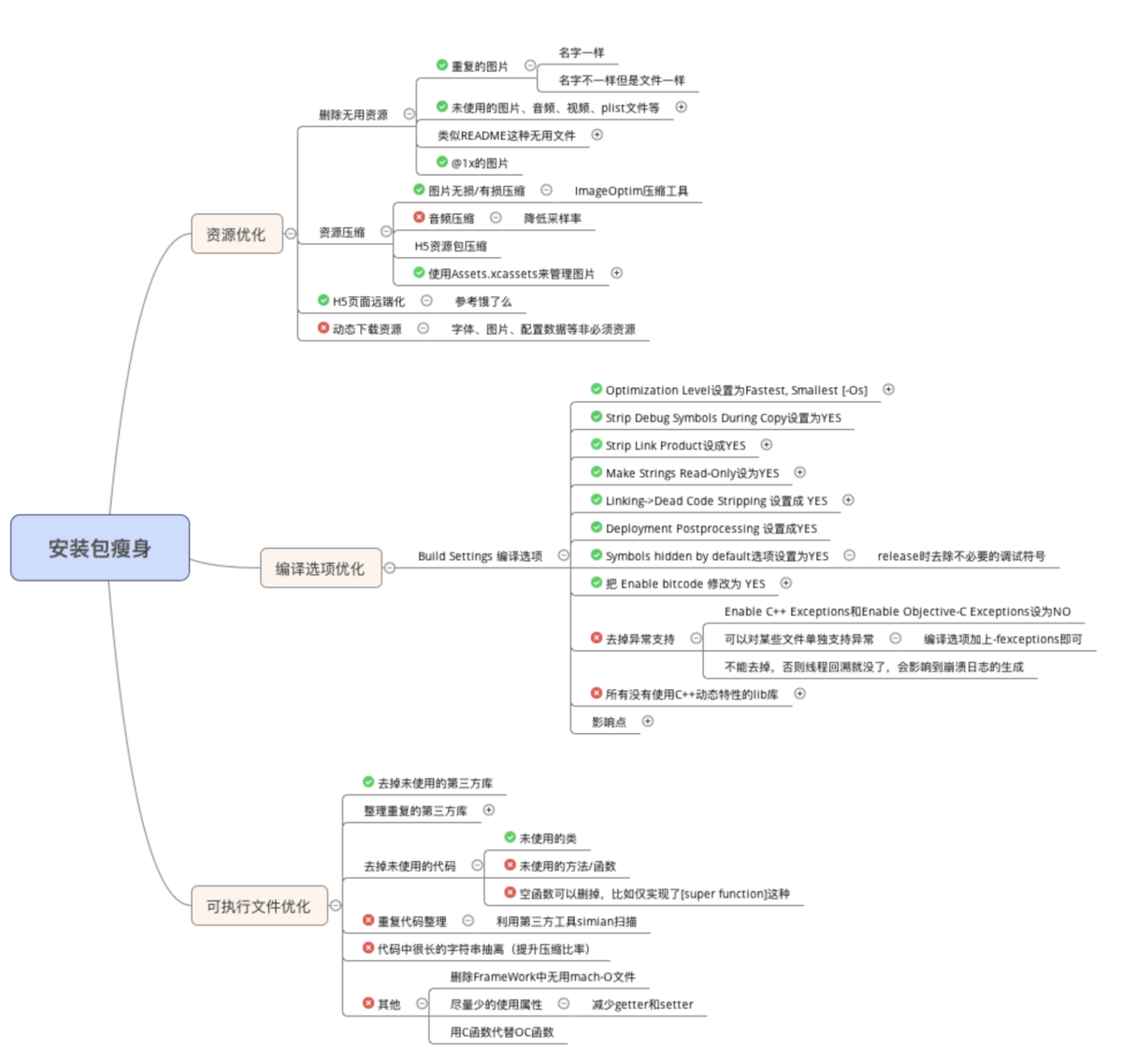
四: 包大小优化
安装包(IPA)主要由可执行文件(源代码文件 编译链接生产的)、资源(图片 音视频 stroyboard xib)组成
项目编译完生产app文件,app文件压缩后成IPA文件1 资源(图片、音频、视频等)采取无损压缩
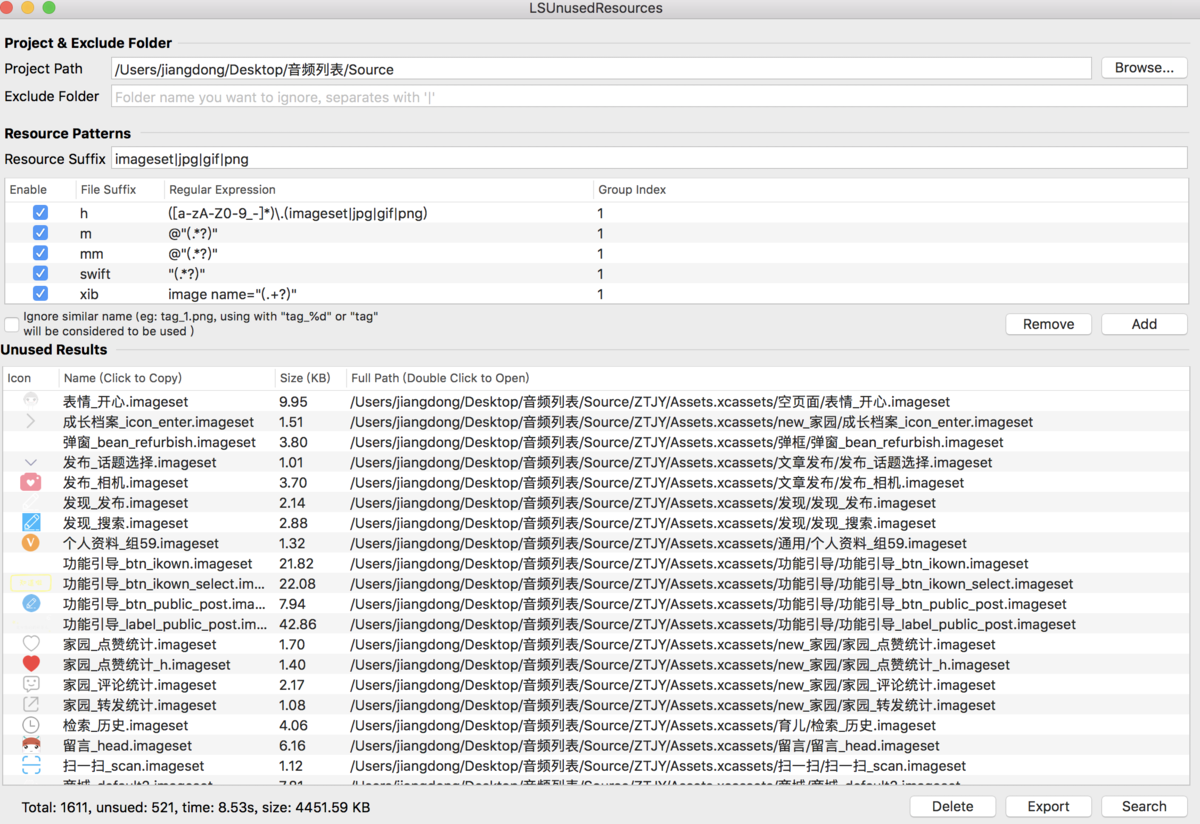
2 去除没有用到的资源: https://github.com/tinymind/LSUnusedResources
无用资源.png
3 编译器优化
Deployment Postprocessing和Strip Linked Product,两个需要都设置为YES才有用。
原理是打开这两个选项后构建ipa会去除掉symbol符号,就是那些类名啊函数名啊啥的。这样子的影响就是运行时你没法进行线程回溯,符号都没了回溯了也是乱码。但是不会影响正常的崩溃日志生成和解析。4 利用AppCode(https://www.jetbrains.com/objc/)检测未使用的代码:菜单栏 -> Code -> Inspect Code
5 手动移除代码
- 梳理项目里的第三方代码,没有直接用的全部删除.
- 梳理用到的第三方代码,如果有功能类似的,移除一个.
- 如果只使用了第三方一部分代码,可以自己实现这个功能,移除这个第三方.
- 项目里旧的类,要及时移除,类里面引用的类也要逐一检查,看是否可以移除
6 视频/音频 大图片资源不要放到包里,可以从服务端下载.
7 图片尽可能放到Assets.xcassets,放进去下载安装包只下载 x2或x3图片.
8 使用 xib/storyboard 来开发视图界面会一定程序增加安装包的大小。尽可能用diamante布局.
9 引入第三方库之前要调研导致包增大多少.
编写LLVM插件检测出重复代码、未被调用的代码
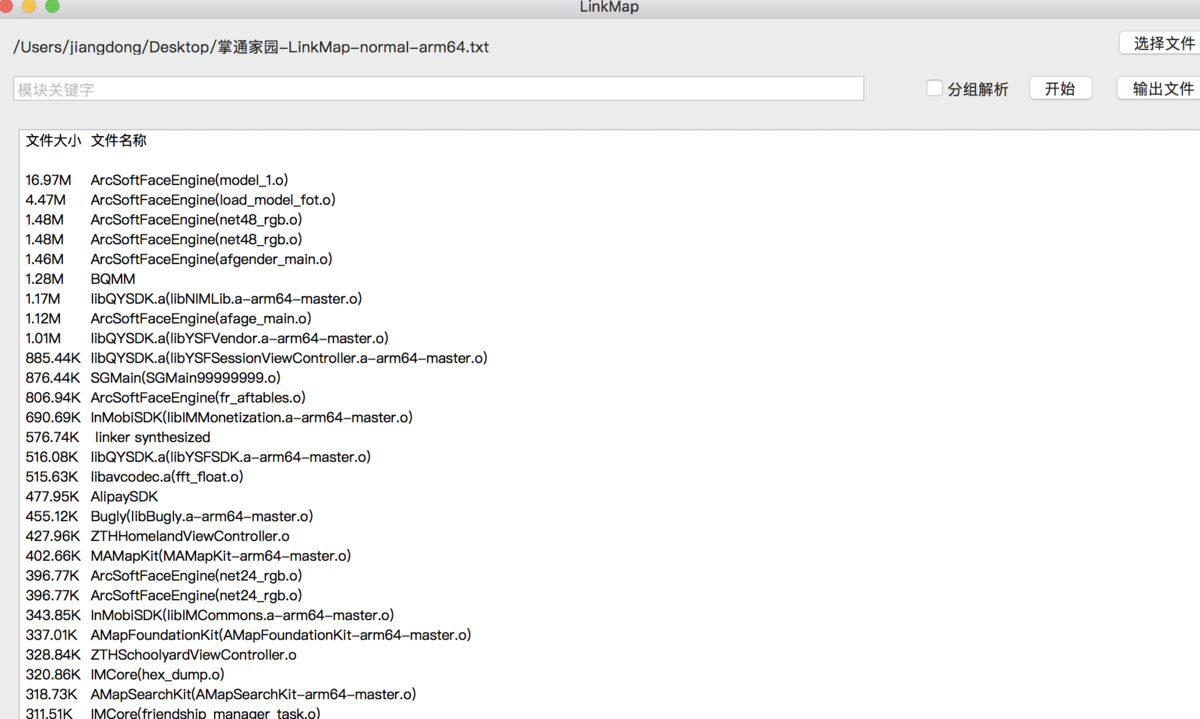
LinkMap分析哪里占用包资源大
Build settings 搜索 link map Write Link Map File 设置成yes, 上面路径前缀设置成桌面,编译后桌面会多一个当前架构下 .txt格式的文件(例如:TImer循环引用-LinkMap-normal-x86_64)
生成LinkMap文件,可以查看可执行文件的具体组成
屏幕快照 2019-03-10 17.37.31.png
可借助第三方工具解析LinkMap文件: https://github.com/huanxsd/LinkMap
掌通代码分析.png
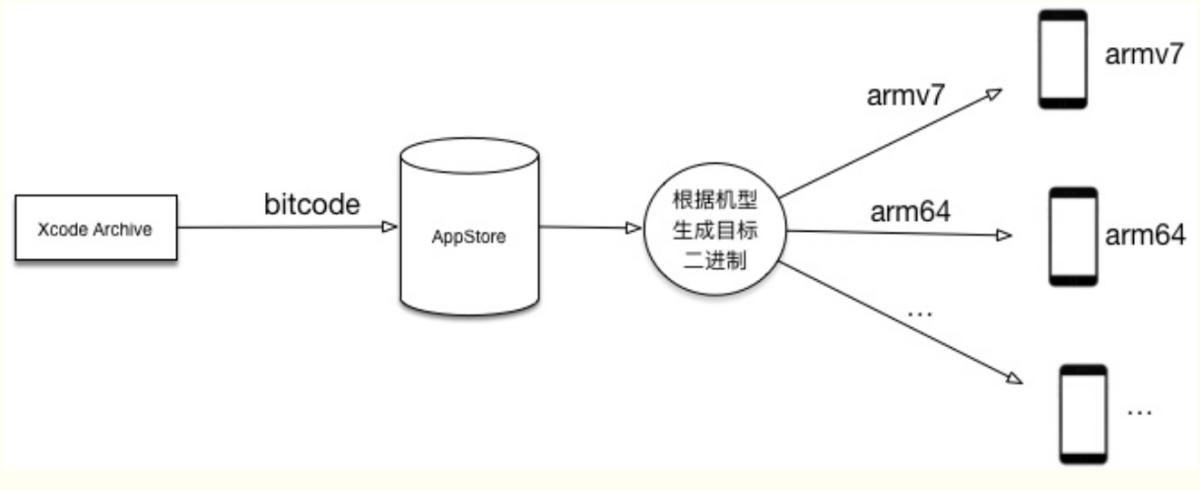
bitcode
Bitcode 类似于一个中间码,被上传到 AppleStore 之后,苹果会根据下载应用的用户的手机指令集类型生成只有该指令集的二进制,进行下发,从而达到精简安装包体积的目的。不同的设备只下载支持自己设备架构的包.
屏幕快照 2019-03-15 上午10.20.56.png
但是如果其中包含第三方库,不支持 Bitcode 时候,需要将 Enable BitCode 设置成 NO。而且这个选项是项目里只要有一个第三方库不支持,就不能开的,否则连接错误。
Other linker flags
Targets选项下有Other linker flags的设置,用来填写XCode的链接器参数,如:-ObjC -all_load -force_load等。
在ios开发中,我们经常会使用到第三方的一些静态库,导入第三方类库运行程序后你会发现,编译时可以正常编译但是运行时会app会闪退,报出selector not recognized的错误。一般的第三方库的开发文档中都会写出这种问题的解决方法,如在Other Linker Flags中加入-ObjC或者-all_load或者-force_load这样的解决方法。为什要这要做呢?报错为什么编译的时候有问题呢,首先我们先引入一个链接器的概念.
还记得我们在学习C程序的时候,从C代码到可执行文件经历的步骤是:
源代码 > 预处理器 > 编译器 > 汇编器 > 机器码 > 链接器 > 可执行文件
在最后一步需要把.o文件和C语言运行库链接起来,这时候需要用到ld命令。源文件经过一系列处理以后,会生成对应的.obj文件,然后一个项目必然会有许多.obj文件,并且这些文件之间会有各种各样的联系,例如函数调用。链接器做的事就是把这些目标文件和所用的一些库链接在一起形成一个完整的可执行文件
那我们为什么要设置Other Linker Flags呢 因为Other Linker Flags其实就是链接器工作时除了默认参数外的其他参数。
运行时的异常时由于静态库, 链接器,与OC语言的动态的特性之间的问题, 如果一个类有了分类,那么链接器就不会将静态库的类与分类之间的代码完成进行合并,这就阻止了在最终的应用程序中的可执行文件缺失了分类中的代码,这样函数调用接失败了.
-ObjC
一般这个参数足够解决前面提到的问题,这个flag告诉链接器把库中定义的Objective-C类和Category都加载进来。这样编译之后的app会变大,因为加载了很多不必要的文件而导致可执行文件变大。
-all_load
但是如果静态库中有类和category的话只有加入这个flag才行,但是Objc也不是万能的,当静态库中只有分类而没有类的时候,Objc就失效了,这就需要使用-all_load或者-force_load了。
-all_load会强制链接器把目标文件都加载进来,即使没有objc代码。但是这个参数也有一个弊端,那就是你使用了不止一个静态库文件,那么你很有可能会遇到ld: duplicate symbol错误,因为不同的库文件里面可能会有相同的目标文件 这里会有两种方法解决 1:用命令行就行拆包. 2:就是用下面的这个参数-force_load
这个flag所做的事情跟-all_load其实是一样的,只是-force_load需要指定要进行全部加载的库文件的路径,这样的话,你就只是完全加载了一个库文件,不影响其余库文件的按需加载 .
如果静态库,不加-ObjC 的话,只把使用到的类加载进来,不会加载分类,会减少一些包大小,但是需要把使用到的功能点一遍,确保没有崩溃.如果部分静态库需要用分类,可以部分分类加-force_load.
十二.常用框架原理
1.SDWebimage
1 | 1、入口 setImageWithURL:placeholderImage:options: 会先把 placeholderImage 显示,然后 SDWebImageManager 根据 URL 开始处理图片。 |
2.AFNetworking
AFNetworking 底层原理分析
AFNetworking是封装的NSURLSession的网络请求,由五个模块组成:分别由NSURLSession,Security,Reachability,Serialization,UIKit五部分组成
NSURLSession:网络通信模块(核心模块) 对应 AFNetworking中的 AFURLSessionManager和对HTTP协议进行特化处理的AFHTTPSessionManager,AFHTTPSessionManager是继承于AFURLSessionmanager的
Security:网络通讯安全策略模块 对应 AFSecurityPolicy
Reachability:网络状态监听模块 对应AFNetworkReachabilityManager
Seriaalization:网络通信信息序列化、反序列化模块 对应 AFURLResponseSerialization
UIKit:对于iOS UIKit的扩展库
十三.编译原理
前端
- 预处理(Pre-process):他的主要工作就是将宏替换,删除注释展开头文件,生成.i文件。
- 词法分析(Lexical Analysis):将代码切成一个个 token,比如大小括号,等于号还有字符串等。是计算机科学中将字符序列转换为标记序列的过程。
- 语法分析(Semantic Analysis):验证语法是否正确,然后将所有节点组成抽象语法树 AST 。Clang 中 Parser 和 Sema 配合完成
- 静态分析(Static Analysis):使用它来表示用于分析源代码以便自动发现错误。
- 中间代码生成(Code Generation):开始IR中间代码的生成了,CodeGen 会负责将语法树自顶向下遍历逐步翻译成 LLVM IR,IR 是编译过程的前端的输出后端的输入。
后端
- 优化(Optimize):LLVM 会去做些优化工作,在 Xcode 的编译设置里也可以设置优化级别-01,-03,-0s,还可以写些自己的 Pass,官方有比较完整的 Pass 教程: Writing an LLVM Pass — LLVM 5 documentation 。如果开启了 bitcode 苹果会做进一步的优化,有新的后端架构还是可以用这份优化过的 bitcode 去生成。
- 生成目标文件(Assemble):苹果平台生成Mach-O
- 链接(Link):生成 Executable 可执行文件。
十四.蓝牙,wifi原理
蓝牙
CoreBluetooth中涉及以下对象类:
- CBCentralManager:中心设备类
- CBPeripheral:外围设备类
- CBCharacteristic:设备特征类
关于蓝牙开发的一些重要的理论概念:
- CoreBluetooth框架的核心其实是两个东西,peripheral和central, 可以理解成外设和中心,就是你的苹果手机就是中心,外部蓝牙称为外设。
- 服务和特征(service and characteristic):简而言之,外部蓝牙中它有若干个服务service(服 务你可以理解为蓝牙所拥有的能力),而每个服务service下拥有若干个特征characteristic(特征你可以理解为解释这个服务的属性)。
- Descriptor(描述)用来描述characteristic变量的属性。例如,一个descriptor可以规定一个可读的描述,或者一个characteristic变量可接受的范围,或者一个characteristic变量特定的单位。
- UUID:蓝牙上的唯一标示符,为了区分不同设备、服务及特征,就用UUID来表示。( iOS不提供MAC地址,所以设备的UUID是由手机的ID和MAC地址算出来的 )
CBCentralMannager 中心模式
以手机(app)作为中心,连接其他外设的场景。详细流程如下:
1.建立一个Central Manager实例进行蓝牙管理
- 扫描外设(discover)
- 连接外设(connect)
- 获得外设中的服务和特征(discover)
4.1 获取外设的services
4.2 获取外设的Characteristics,获取Characteristics的值,- 获取外设服务特征(Characteristics)的Descriptor和Descriptor的值
- 从外围设备读数据(直接读取和订阅两种方法)
- 与外设做数据交互(explore and interact)
- 断开连接(disconnect)
CBPeripheralManager 外设模式
- 建立外设角色
- 设置本地外设的服务和特征
- 发布外设和特征
- 广播服务
- 响应中心的读写请求
- 发送更新的特征值,订阅中心
wifi
AP(Access Point):
无线接入点,这个概念特别广,在这里,用大白话说,你可以把CC3200当做一个无线路由器,这个路由器的特点不能插入网线,没有接入Internet,只能等待其他设备的链接,并且智能接入一个设备。类似于点对点模式啦。
STA(Station):任何一个接入无线AP的设备都可以称为一个站点。大白话说也就是平时接入路由器的设备
SSID(Service Set Identifier):
SSID,每个无线AP都应该有一个标示用于用户识别,SSID就是这个用于用户识别的的名字,也就是我们经常说到的wifi名。
BSSID:
每一个网络设备都有其用于识别的物理地址,这个东西呢就叫MAC地址,这个东西一般情况下出厂会有一个默认值,可更改,也有其固定的命名格式,也是设备识别的标识符。这个BSSID呢是针对设备说的,对于STA的设备来说,拿到AP接入点的MAC地址就是这个BSSID。
ESSID:
是一个比较抽象的概念,它实际上就和ssid相同(本质也是一串字符),只是能如果有好几个无线路由器都叫这个名字,那么我们就相当于把这个ssid扩大了,所以这几个无线路由器共同的这个名字就叫ESSID。(也就是如果在一台路由器上释放的wifi信号叫某个名字如“China_CMCC”,这个名字“China_CMCC”就称为SSID;如果在好几个路由器上都释放了这个wifi信号,那么大家都叫“China_CMCC”,这个时候大家都遵循的这个名字就是ESSID
举个例子,一家公司面积比较大,安装了若干台无线接入点(AP或者无线路由器),公司员工只需要知道一个SSID就可以在公司范围内任意地方接入无线网络。BSSID其实就是每个无线接入点的MAC地址。当员工在公司内部移动的时候,SSID是不变的。但BSSID随着你切换到不同的无线接入点,是在不停变化的。
用戏称来说,bssid就是具体的某个连锁店编号(001)或地址,ssid就是连锁店的名字或者照片,essid就是连锁店的总公司或者招牌or品牌。一般ssid和essid都是相同的。
RSSI:
这个理解起来更简单,就是通过STA扫描到AP站点的信号强度。
关于flutter相关问题
- Flutter 的优势是什么?
- Flutter 提供了快速开发高质量、流畅的跨平台应用的能力。
- 使用 Dart 语言开发,具有强大的性能和灵活性。
- 采用自绘 UI 的方式,可实现高度定制化的界面。
- 拥有丰富的组件库,便于开发者构建各种复杂的用户界面。
- Widget 是什么?Flutter 中有哪些常用的 Widget?
- Widget 是 Flutter 中构建用户界面的基本单元,可以是简单的文本或图像,也可以是复杂的组合组件。
- 常用的 Widget 包括:Text、Image、Container、Row、Column、ListView、GridView、Stack、AppBar 等。
- StatefulWidget 和 StatelessWidget 有什么区别?
- StatefulWidget 具有可变状态,可以在运行时发生变化,通常用于需要响应用户交互或者数据变化的界面。
- StatelessWidget 是不可变的,其内容在构建时确定且不可更改,适用于静态内容或者不需要更新的界面。
- 什么是 State Management?Flutter 中有哪些常用的状态管理方式?
- State Management 是管理应用状态的方式,用于管理数据在不同 Widget 之间的共享和更新。
- Flutter 中常用的状态管理方式包括:setState、Provider、Bloc、Redux、GetX 等。
- Flutter 中的网络请求如何实现?
- 可以使用 Dart 提供的 http 或 dio 等库进行网络请求,通过 Future 或者 async/await 实现异步操作。
- 在 Flutter 中通常使用 FutureBuilder 或者 StreamBuilder 来处理异步数据并更新界面。
- 如何优化 Flutter 应用的性能?
- 减少 Widget 的重建次数,使用 const 构造函数或者将不变的 Widget 抽取成 StatelessWidget。
- 使用 ListView.builder 或者 GridView.builder 等懒加载列表,避免一次性加载大量数据。
- 使用图片、字体等资源时,尽量使用高效的格式并进行优化。
- Flutter 中的路由是如何管理的?
- Flutter 中的路由管理使用 Navigator,可以通过 push 和 pop 进行页面的跳转和返回。
- 可以使用 MaterialPageRoute 或自定义的 PageRoute 来实现不同的页面切换效果。
- Flutter 的国际化和本地化如何实现?
- 可以使用 Flutter 提供的 intl 包来实现多语言支持和本地化。
- 通过 Intl.message 函数定义不同语言的消息文本,并在应用中动态加载对应的语言资源。
关于H5相关问题
Vue.js 是什么?有哪些特点?
- Vue.js 是一套用于构建用户界面的渐进式框架,易于学习和使用。
- 特点包括数据驱动、组件化、响应式更新、简洁灵活等。
Vue.js 的生命周期钩子有哪些?分别在何时调用?
- beforeCreate、created:在实例初始化之后,数据观测和事件配置之前调用。
- beforeMount、mounted:在模板编译挂载到 DOM 之前和之后调用。
- beforeUpdate、updated:在数据变化导致虚拟 DOM 重新渲染和打补丁之前和之后调用。
- beforeDestroy、destroyed:在实例销毁之前和之后调用。
Vue.js 的双向数据绑定是如何实现的?
- Vue.js 使用了 Object.defineProperty 或者 Proxy 对象来劫持数据的 get 和 set 操作,实现了响应式数据绑定。
Vue.js 的组件通信方式有哪些?
- 父子组件通信:props 和 $emit。
- 子父组件通信:$emit 和 $on。
- 兄弟组件通信:事件总线、Vuex、provide/inject 等。
Vue.js 的路由是如何实现的?
- Vue Router 是 Vue.js 官方的路由管理器,通过路由配置和组件结合实现单页面应用(SPA)的路由跳转和管理。
Vue.js 中的 Vuex 是什么?有什么作用?
- Vuex 是 Vue.js 官方的状态管理库,用于管理应用中的全局状态和数据流。
- 它的作用包括集中式状态管理、状态共享、方便的状态调试等。
Vue.js 的指令有哪些?举例说明用法。
- v-bind:绑定 HTML 属性。
- v-on:绑定事件监听器。
- v-model:实现表单元素和数据的双向绑定。
- v-for:循环渲染列表数据。
- v-if、v-else、v-show:条件性地渲染元素等。
Vue.js 的过滤器是什么?如何使用?
Vue.js 的过滤器用于处理文本的格式化,可以在模板中使用管道符号(|)来应用过滤器。
例如:,其中 capitalize 是一个自定义的过滤器,用于将消息文本转换为首字母大写。
未完待续
if #available(iOS 11.0, *) {
self.tableView.contentInsetAdjustmentBehavior = .never} else {
self.automaticallyAdjustsScrollViewInsets = false}
对称加密算法有DES、3DES、TDEA、Blowfish、RC5和IDEA
学习方向: 1. Leedcode 2.第三方源码解读和模仿 3.RXSwift 4.C++ 5.FFmpeg 6.openGL
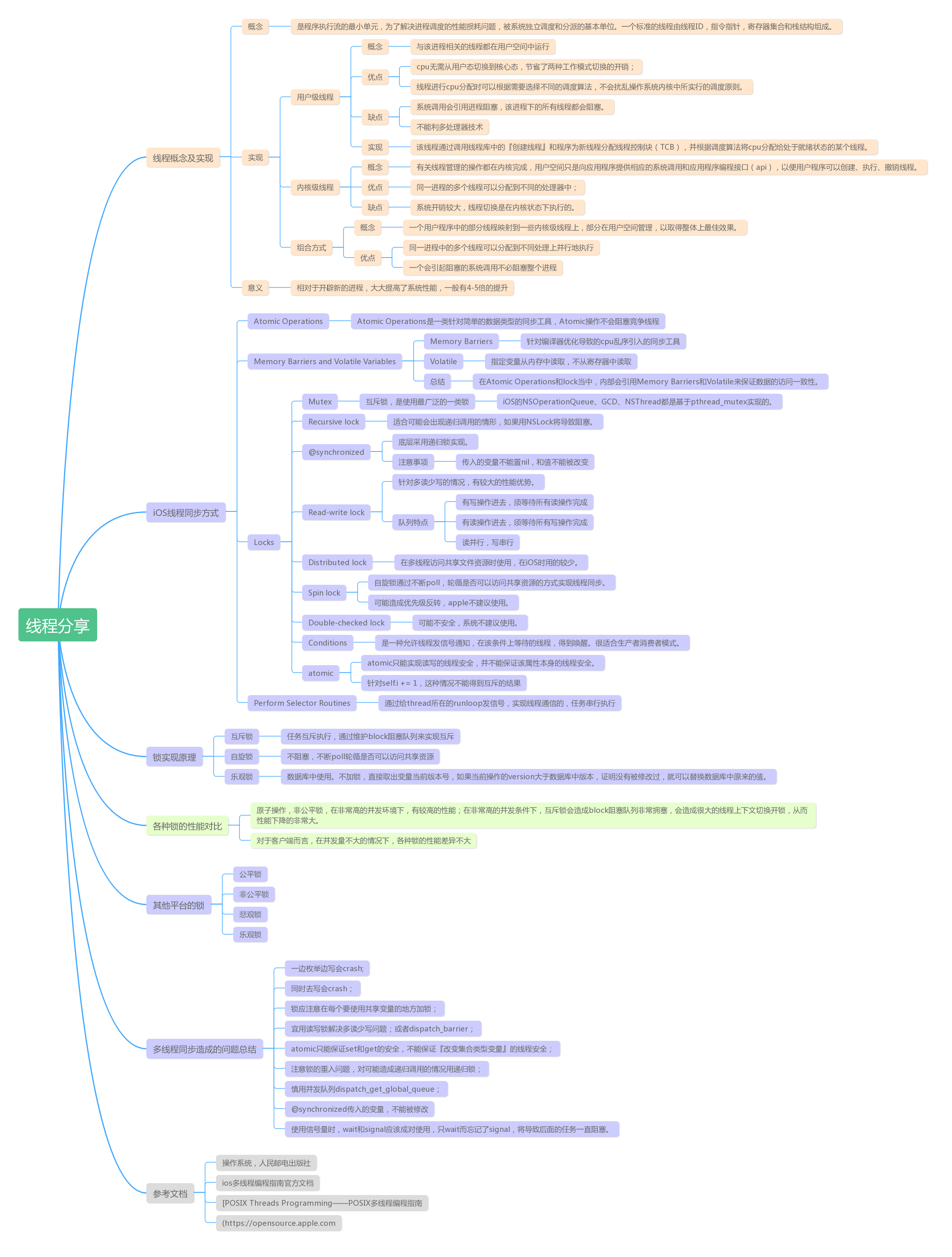
线程图解
经典算法题
1. N级台阶 一次可以跳1级 也可以跳2级 总共多少种跳法
- 我们可以定义一个数组
dp,其中dp[i]表示跳到第i级台阶的跳法总数。 - 初始条件是
dp[1] = 1,表示跳到第1级台阶只有一种跳法;dp[2] = 2,表示跳到第2级台阶有两种跳法。 - 然后,我们可以用动态规划的方式计算
dp[i],根据题意,跳到第i级台阶有两种方式:从第i-1级跳1级,或者从第i-2级跳2级。因此,dp[i] = dp[i-1] + dp[i-2]。 - 最终,
dp[N]即为所求的总跳法数。
2.有100瓶药水,其中一瓶是毒药,只要一小滴,就足以让小白鼠24小时内死亡。请问怎么在1天内用最少的老鼠找出这瓶毒药
假设我们有100瓶药水,编号从1到100。我们将这100瓶药水的编号转换成二进制格式,然后根据每一位二进制位的值来确定哪些药水含有毒药。例如,编号为1的药水的二进制表示为00000001,编号为2的药水的二进制表示为00000010,依此类推。
我们将100瓶药水的编号从1到100按照如下方式排列:
1 | 1 00000001 |
现在我们让第一只小白鼠尝试编号为1的药水,第二只小白鼠尝试编号为2的药水,依此类推,每只小白鼠尝试的药水编号对应着二进制位上为1的药水。例如,第一只小白鼠尝试的药水编号为1、3、5、7、…,第二只小白鼠尝试的药水编号为2、3、6、7、…,依此类推。
每只小白鼠死亡的结果对应着药水编号的二进制位上为1的位置,最终我们将每只小白鼠死亡的药水编号转换成二进制格式,然后将这些二进制数相加,得到的结果即为含有毒药的药水编号。
这种方法的关键在于将100瓶药水的编号按照二进制格式排列,使得每只小白鼠死亡的结果能够提供关于毒药位置的信息,从而最小化实验所需的小白鼠数量
3.在从1到n的正数中1出现的次数
- 数位分析:
- 对于每个位数(个位、十位、百位等),分别计算数字1出现的次数,然后将所有位数的次数相加即可得到总次数。
- 以n=12345为例,分别计算个位、十位、百位、千位和万位上数字1出现的次数,然后相加。
具体步骤如下:
- 首先,从个位开始逐位计算数字1出现的次数。
- 对于当前位数(假设为x),将数字n分为两部分:高位和低位。高位是当前位及更高位的数字,低位是当前位以下的数字。
- 分情况讨论:
- 如果当前位数x为0,则当前位上数字1出现的次数为高位数字乘以当前位数的权重(例如,对于百位,权重为100)。
- 如果当前位数x为1,则当前位上数字1出现的次数为高位数字乘以当前位数的权重,再加上低位数字加1。
- 如果当前位数x大于1,则当前位上数字1出现的次数为(高位数字加1)乘以当前位数的权重。
4.一类似于蜂窝的结构的图,进行搜索最短路径(要求5分钟)
广度优先搜索(BFS)算法是一种图搜索算法,用于从起始节点开始搜索图中的节点,直到找到目标节点或者遍历完所有可达节点。以下是BFS算法的原理描述:
- 初始化:
- 创建一个空队列(通常使用队列数据结构)用于保存当前待访问的节点。
- 将起始节点放入队列中,并标记起始节点为已访问。
- 循环搜索:
- 在队列不为空的情况下,循环执行以下步骤:
- 从队列中取出一个节点作为当前节点。
- 检查当前节点是否是目标节点,如果是,则搜索结束,返回当前节点到起始节点的最短路径。
- 否则,将当前节点的所有未访问过的相邻节点加入队列,并标记这些相邻节点为已访问。
- 重复以上步骤,直到队列为空或者找到目标节点为止。
- 在队列不为空的情况下,循环执行以下步骤:
- 搜索结果:
- 如果队列为空而且仍未找到目标节点,则表示图中不存在从起始节点到目标节点的路径。
- 如果找到目标节点,则可以通过回溯到起始节点的路径来得到最短路径。
BFS算法的关键在于利用队列数据结构进行层级遍历,从而保证搜索到的路径是最短路径。每次从队列中取出一个节点时,都会将其所有未访问过的相邻节点加入队列,保证了搜索的广度优先性质。这样一层一层地搜索,直到找到目标节点或者搜索完所有可达节点,从而得到最短路径。